

Introduction
In today’s landscape, companies face the critical challenge of effectively managing vast amounts of data while safeguarding personal information. As the volume and complexity of data grow, accurately identifying and managing personal data becomes increasingly difficult. To address this, organizations need solutions equipped with rapid and precise data analysis capabilities, enabling them to enhance their data protection standards significantly.
Challenges
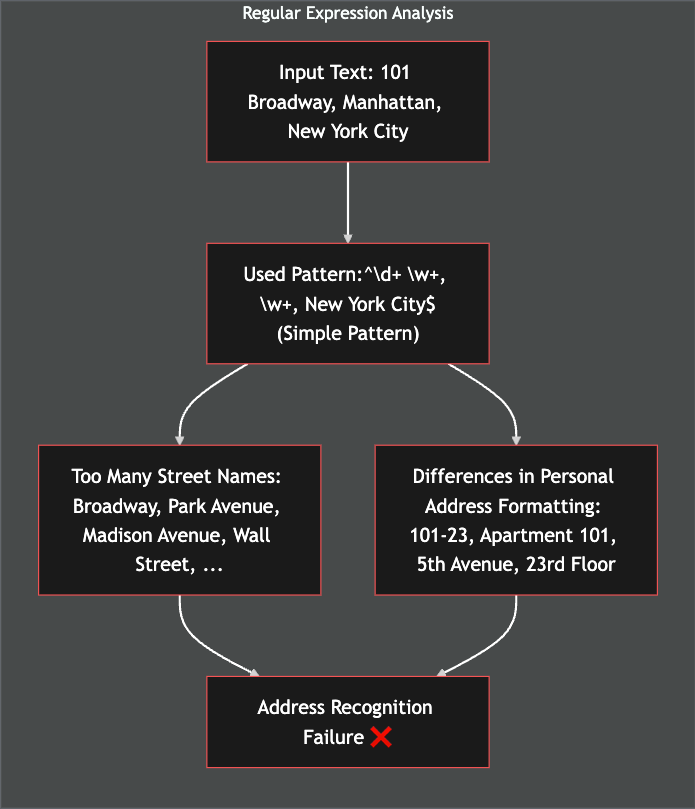
Accurately classifying personal data in large-scale databases is a significant challenge faced by many organizations. Traditional methods based on regular expressions and fixed pattern recognition are losing effectiveness due to the following limitations:
- Diversity of Data Patterns
- Personal information such as addresses, names, and medical records often lacks standardized formats, making classification difficult.
- Examples:
- Addresses can appear as “110-2430” or “bldg 110 rm. 2430,” presenting varying structures.
- Medical data can include abbreviations or technical jargon, increasing complexity.
- Complexity of Regulatory Compliance
Global regulations such as GDPR, CCPA, HIPAA, and ISO/IEC 27701 mandate precise identification and protection of personal data. Failing to comply can result in legal issues, fines, and a decline in customer trust.
- GDPR (General Data Protection Regulation): Enforces transparency in data handling and ensures the rights of EU data subjects.
- CCPA (California Consumer Privacy Act): Grants California consumers the right to request data deletion and opt-out of data sales.
- HIPAA (Health Insurance Portability and Accountability Act): Protects sensitive health information in the US, ensuring confidentiality and security.
- ISO/IEC 27701: Provides an international framework for managing personal information and supporting regulatory compliance.
Each regulation presents unique requirements, and non-compliance exposes organizations to severe legal, financial, and reputational risks.
-
Inefficiency of Traditional Solutions
- Regular expression-based systems only recognize predefined patterns and require frequent updates for new data formats.
- This decreases operational efficiency and leads to increased costs for organizations.
These challenges weaken data protection, increase operational costs, and leave organizations vulnerable to compliance and security risks.
Objectives
The objective of the AI classifier is to enable customers to gain tangible benefits in data protection and management. By addressing the complexities of data management, improving the level of personal data protection, and achieving regulatory compliance effectively, this solution aims to deliver the following core goals:
1. Enhancing the Accuracy of Personal Data Identification
- Context-Based Automated Classification: Rather than relying on fixed patterns, the AI classifier comprehends data contextually to accurately identify various types of personal data, such as addresses, names, and medical information.
- Adaptation to New Data Patterns: The AI model continuously learns, overcoming the limitations of traditional solutions and adapting flexibly to new data patterns.
This significantly improves the accuracy of personal data identification, minimizing errors and uncertainties in data management for customers.
2. Boosting Operational Efficiency and Reducing Costs
- Resource Savings: High-performance classification reduces the workload on IT, security, and data management teams, even in large-scale data environments.
- Time Optimization: Processes diverse data quickly, reducing the time spent on repetitive tasks.
- Operational Stability: The AI classifier provides high reliability and consistency during data processing, preventing system interruptions or errors and maintaining a stable operational environment.
By leveraging the AI classifier, organizations can enhance the efficiency of personal data management and allocate more resources to their core business activities.
3. Supporting Regulatory Compliance
- Automated Regulatory Response: Aligns with regulations such as GDPR, CCPA, HIPAA, and ISMS-p by automating classification tailored to legal requirements.
- Real-Time Monitoring and Reporting: Provides transparent data management and reporting capabilities to demonstrate compliance.
- Mitigation of Legal Risks and Fines: Prevents penalties and reputational damage caused by regulatory violations, enhancing corporate trustworthiness.
With these, organizations can ensure compliance, minimize legal risks, and strengthen customer trust effectively.
Solution Overview
QueryPie’s AI classifier is a solution that combines contextual analysis and pattern recognition to classify personal data with precision and efficiency. This helps customers simplify complex data management processes and enhance personal data protection. The AI classifier offers the following key features:
1. Advanced Text Comprehension
- Leverages bidirectional contextual understanding to analyze and classify data containing personal information accurately.
- Handles various types of personal data, including names, addresses, and medical information, ensuring high accuracy for both structured and unstructured data.
- Adapts flexibly to data by understanding its context, avoiding reliance on fixed patterns.
2. Reliable Data Collection and Refinement
- Collects necessary data for personal information classification from credible sources such as national databases and public data portals.
- The collected data undergoes refinement processes, including deduplication, error correction, and standardization, to ensure high-quality training data.
- Refined data is a critical factor in improving classification accuracy, providing results tailored to the customer’s environment.
3. Customized Classification Models
- Offers models optimized for different types of personal information.
- For instance, separate AI models are designed for names, addresses, and medical information to maintain high accuracy.
- Adjusts models to meet customer-specific requirements across various industries and data environments.
- Continuously learns and updates to adapt flexibly to new data patterns.
4. Efficient Resource Utilization
- Features advanced pre-filtering capabilities to filter out irrelevant text, maximizing processing efficiency.
- Minimizes unnecessary model calls to optimize system resource usage, reducing operational costs effectively.
Technical Description
Background for Model Selection
To optimize performance for personal data classification tasks, various AI language models were analyzed and compared. The BERT-based model was selected due to its specific advantages for personal data classification over recently developed large language models like GPT or Claude:
- Efficient Processing Speed
- BERT provides an excellent balance between processing speed and accuracy for real-time classification tasks.
- It operates reliably in large-scale data environments, minimizing latency issues during processing.
- Context Understanding and Feature Extraction
- BERT excels in analyzing text context both forwards and backwards, making it highly effective at accurately classifying personal data.
- Whether dealing with names, addresses, or medical records, BERT consistently delivers high precision in handling various types of personal information.
- Model Combination and Optimization
- Different models were selected and optimized based on the specific types of personal data being classified:
- KoElectra: An open-source model optimized for Korean language datasets. It performs exceptionally well in tasks such as medical record classification and address identification. (For Korean market)
- Custom BERT-Based Model: A BERT model trained on tailored datasets offers robust performance, especially in handling Out-of-Vocabulary (OOV) issues caused by short text or abbreviations. It surpasses open-source models in stability and accuracy for such challenges.
- By combining these models, the strengths of each are maximized to address various types of personal data effectively.
- Different models were selected and optimized based on the specific types of personal data being classified:
- High Accuracy and Flexibility
- The system leverages the strengths of multiple models to achieve high accuracy in personal data classification tasks.
- With its robust learning and updating framework, the system can flexibly adapt to new data patterns and changes in environmental conditions.
Solution Components Overview
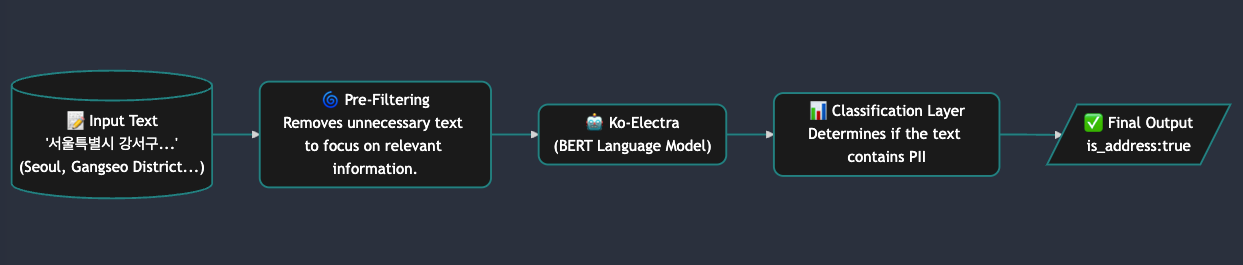
The personal data classification process of the AI classifier is designed in sequential stages to maximize accuracy and efficiency. Below is a detailed explanation of each component:
1. Pre-Filtering
- Role: Analyzes input sentences to remove irrelevant text unrelated to personal data and filters out unnecessary content, allowing the model to focus on meaningful data.
- Effect: Reduces the amount of data the model needs to process, optimizing resource usage, and improves processing speed by filtering out irrelevant data early.
- Examples:
- Text Consisting Solely of Special Characters or Numbers:
Strings like
"123456"or"!@#$%^&*"are unlikely to be relevant to personal information such as addresses or medical data. Therefore, they are excluded from the analysis stage. - Text Misaligned with Personal Data Types:
For example, Korean text such as
"홍길동"(a name written in Hangul) is excluded from the Romanized name classifier. Conversely, Romanized names like"Gil-Dong Hong"are passed to the Romanized name classifier for further processing.
- Text Consisting Solely of Special Characters or Numbers:
Strings like
2. Context Analysis Model
- Role: Utilizes BERT-based language models like Ko-Electra to perform deep contextual analysis of input text.
- Effect: Goes beyond simple keyword matching by understanding the meaning within context to accurately determine whether the text contains personal information.
- Features:
- Handles complex data types such as addresses, names, and medical information.
- Adapts flexibly to new and evolving data patterns.
3. Classification Layer
- Role: Uses the feature vectors extracted by the context analysis model to make a final determination on whether the text contains personal information.
- Effect: Accurately identifies personal information and structures the results in a format suitable for the client environment.
- Example Output:
- If the input text contains address information, the output might be formatted as:
"is_address: true" - This clearly communicates the presence of personal information and simplifies the data structure for seamless integration into subsequent processes.
- If the input text contains address information, the output might be formatted as:
Data Collection and Refinement

1. Data Collection
We gather data essential for personal information classification from trustworthy public sources and verified platforms. In this section, I will explain based on examples from Korean data sources.
- Reliable Data Sources: Data is obtained from credible sources such as (in Korean case):
- Diverse Data Types:
- Address Data: We utilize Korean address data from the Address-based Industry Support Services. This includes city, county, and district information, which is combined to generate realistic or similar address data for training.
- Medical Information: Medical terms and abbreviations are extracted from statistics such as frequent disease conditions and disease frequency data provided by the Healthcare Big Data Open System.
- Occupations and Certifications: Occupational and certification-related data are sourced from the Korean Occupational Dictionary and PQI (Private Qualification Information Service).
- Ensuring Accuracy: We ensure the credibility of data sources and strictly manage quality during the collection phase.
2. Data Refinement
The collected data undergoes a refinement process to ensure consistency and quality before being utilized.
- Duplicate Removal: Identical data entries are removed to prevent redundant learning in the model.
- Error Correction: Mistakes and omissions are reviewed and corrected. For example, typos or incorrect syntax in address data are fixed.
- Standardization: Data is made uniform through removing special characters, eliminating unnecessary spaces, and building an abbreviation dictionary.
- Quality Assurance: Refined data is sampled and reviewed to ensure accuracy and relevance to the model.
Classification Workflow
1. AI Classifier Training
The AI classifier undergoes a tailored training process to ensure high accuracy by incorporating characteristics specific to different types of personal data.
- Fine-tuning Process:
- Base language models (e.g., BERT or Ko-Electra) are fine-tuned specifically for personal data classification tasks.
- Training is segmented by data types, such as names, addresses, medical information, and occupations.
- Data Augmentation:
- Diverse data formats are introduced during training to help the model adapt to new patterns.
- Example:
- Recognizing that
"123 5th Ave, Manhattan, NY"and"123 Fifth Avenue, New York, NY"refer to the same address format.
- Recognizing that
- Overfitting Prevention:
- Techniques like early stopping and dropout are employed to prevent the model from overly fitting the training data.
2. Text Classification
The trained AI classifier processes input data in real time, identifying personal information and providing structured outputs.
- Real-Time Analysis Process:
- The model analyzes the context of input text and quickly determines whether it contains personal information.
- Example:
- Input Data:
"123 5th Ave, Manhattan, NY" - Analysis Result:
- Classified as an "address."
- Output: Provided in a structured format for easy integration with the customer's system.
→
{ is_address: true, text: "123 5th Ave, Manhattan, NY" }
- Input Data:
- Customizable Classification Criteria:
- Classification rules can be adjusted to meet business-specific requirements.
- Use Case: Configure the system to focus only on analyzing addresses and names.
Accuracy of the AI Classifier
The QueryPie AI Classifier achieves high accuracy in personal data classification through meticulous data preparation and evaluation processes. The performance of the deep learning model is evaluated and continually improved using the following methodologies:
1. Dataset Composition and Evaluation Methodology
- Training Dataset: Utilizes large-scale, categorized data based on different types of personal information to train the model.
- Testing Dataset: Completely separate from the training dataset to evaluate the model's performance accurately.
- Reflects real-world distributions and incorporates diverse data patterns to validate the model's generalization capabilities.
- Reflecting Real-World Data:
- In real environments, unexpected new data patterns often emerge.
- To address this, virtual data generation and data augmentation techniques are employed to expose the model to varied scenarios.
- Example: Data such as
"1600 Pennsylvania Avenue NW, Washington, DC 20500"and"1600 Penn Ave, Washington, DC"are both used to train the model to recognize multiple formats of the same address.
2. Overfitting Prevention Techniques
The QueryPie AI Classifier leverages advanced techniques to prevent overfitting and enhance generalization performance, including:
- Early Stopping
- Halts training when validation performance (e.g., loss or accuracy) plateaus for a specified period.
- Example: During training, when validation loss did not improve for five consecutive epochs, training was automatically stopped at epoch 15, preventing overfitting and conserving resources.
- Dropout
- Randomly deactivates a portion of neurons during training to reduce dependency on specific features and enhance model robustness.
- Example: A dropout rate of 30% was applied in the address classification network, allowing the model to handle unfamiliar address formats effectively.
- Batch Normalization
- Normalizes the inputs to each layer to stabilize the training process and mitigate overfitting risks.
- Example: Applied to job classification tasks, batch normalization improved training stability and accelerated optimization.
- Data Augmentation
- Creates new training samples by transforming existing data to increase dataset diversity.
- Example: Transformed
"1600 Pennsylvania Ave"to"1600 Penn Ave"or"John Smith"to"J. Smith"to teach the model to handle various representations.
3. Accuracy and Performance Results
The AI classifier demonstrates exceptional accuracy across multiple categories of personal data:
| Classification Category | Accuracy |
|---|---|
| Korean Names | 98.9% |
| Romanized Korean Names | 96.7% |
| Addresses | 99.1% |
| Country Codes | 97.8% |
| Occupations | 99.2% |
| Certifications | 99.2% |
| Medical Information | 98.8% |
This high level of accuracy is the result of optimizing BERT models—either through open-source frameworks or custom training—and separately training classification layers tailored to each type of personal information. These efforts form the foundation of QueryPie's success, ensuring robust and specialized data classification.
Building on these achievements, we are committed to preventing overfitting and further improving performance by continuously acquiring diverse datasets and refining our training processes. Through these ongoing improvements, customers can experience stable and reliable classification performance, even in evolving data environments, and benefit from more precise personal data protection services.
Model Optimization and Deployment Strategy
To maintain the high performance and efficiency of QueryPie's AI classification system, we have meticulously designed strategies for model optimization and deployment. These strategies ensure stable and rapid responses in real-time classification environments.
1. Model Optimization Strategy
- Model Lightweighting:
- We evaluated BERT-based models and various open-source alternatives (e.g., KoElectra) to identify the optimal balance between response speed and accuracy.
- Lightweighting efforts focused on reducing model complexity while preserving high performance, significantly improving processing speed.
- Example: Optimized the number of parameters for text classification tasks to minimize unnecessary computations and reduce resource usage.
- Enhanced Real-Time Classification Performance:
- The lightweighted models are well-suited for real-time data processing and deliver consistent performance across datasets of varying sizes.
- The model architecture is designed to flexibly adapt to emerging data patterns, ensuring quick adjustments to new inputs.
2. Efficient Deployment Strategy
- Container-Based Deployment:
- The classification models are deployed in lightweight environments using containerization technology.
- This approach simplifies deployment and enables seamless integration across diverse IT ecosystems.
- Resource Management and Stability:
- To optimize CPU and memory usage, environment variables are used to set resource usage limits.
- Stable performance is ensured even in scenarios requiring parallel execution of classification tasks.
- Example: Maintains response speed and prevents resource exhaustion during large-scale data processing.
- Enhanced Security:
- Multistage builds are employed in the deployment environment to remove unnecessary files and layers, achieving both lightweighting and enhanced security.
- Up-to-date base images are used to minimize potential security vulnerabilities.
Vision for Future Growth and Expansion
QueryPie’s AI classification system is poised to become the ultimate solution for personal information protection and data management in global markets. By offering localized services tailored to regional legal regulations and cultural differences, we aim to ensure high reliability and performance across diverse data environments.
1. Expanding to Global Markets
- Localized Services:
- Analyze each country's personal data protection laws (e.g., GDPR, CCPA) and regulations to offer customized solutions that meet local requirements.
- Example: In Europe, emphasize GDPR-compliant data processing; in the U.S., focus on CCPA's right-to-delete requests and data sale opt-out features.
- Incorporating Language and Cultural Differences:
- Develop multilingual support models that account for linguistic nuances, enabling accurate personal information classification in various languages.
- Example: In Korean, "PD" refers to a television producer, while English uses "Producer" or "Television Producer." Such differences are incorporated into training data.
- Region-Specific Technology Adaptation:
- Optimize systems based on commonly used data formats and structures in specific regions.
- Example: Japanese addresses are written from larger regions (prefectures) to smaller ones (blocks), whereas German addresses use the reverse order. Classification models will account for these regional differences.
2. Performance and Scalability Enhancements
- Improved Multilingual Performance:
- Build on the high performance of existing models, ensuring similar results across new languages and regions through ongoing optimization.
- Expand testing and validation datasets to guarantee stable performance with new languages and data patterns.
- Broader Data Diversity:
- Integrate data specialized by region and industry to provide solutions applicable in domains such as healthcare, finance, and public services.
- Example: Train models on data containing medical abbreviations, financial jargon, and public sector-specific terminology.
3. Customer-Centric Services
- Addressing Customer Needs:
- Identify and resolve specific problems faced by customers in different regions by offering tailored features.
- Example: Provide automated regulatory compliance reports or real-time alert systems to address local compliance challenges.
- Consistent User Experience:
- Deliver uniform, high-quality services across regions, ensuring that customers can trust QueryPie’s AI solutions regardless of changes in their data environments.
Conclusion
QueryPie has developed AIDD (AI Data Discovery), an advanced AI-powered classifier, to address critical challenges in personal data protection with precision and efficiency. Traditional rule-based systems relying on static patterns often fall short when handling diverse and dynamic forms of personal information. In contrast, QueryPie’s AI classifiers leverage contextual analysis and pattern recognition to accurately identify complex and evolving data types, including addresses, names, and medical records.
These innovations provide the following key benefits to customers:
- Enhanced Data Protection: Accurately classifies diverse personal data types, reducing complexity and strengthening data protection.
- Regulatory Compliance: Designed to meet global regulations like GDPR and CCPA, minimizing legal risks.
- Operational Efficiency: Delivers fast and accurate classification, saving time and costs while providing solutions optimized for customer business environments.
QueryPie will continue to improve the stability and performance of its AI classifiers through techniques like overfitting prevention, dataset expansion, and continuous learning. The system’s flexibility enables swift adaptation to new data environments and evolving customer requirements, ensuring reliable service delivery.
Additionally, QueryPie plans to expand its AIDD solutions globally across North America, Europe, and Asia-Pacific, offering localized services tailored to regional privacy laws and regulations. This ensures a consistent level of protection and performance for clients worldwide, allowing them to experience a high standard of trust in data protection and management across geographies.
Appendix
References
- Integrated Job Dictionary - Ministry of Employment and Labor, Korea
- Healthcare Big Data Open System - Health Insurance Review and Assessment Service
- PQI (Private Qualification Information Service) - Certificate Listings
- Korean Address Dataset - Address Industry Support Service
- Romanization Rules for Korean Names
- Electronic Family Relationship System
- National Statistical Portal
- Wikipedia Dump Data (Korean and English)
- Korean Naver Blog Comment Dataset
- National Institute of Korean Language Dictionary
- National Institute of Korean Language Corpora - Newspaper Corpus 2022
Curious?
Reveal the Magic!
Please fill out the form to unlock your exclusive content!