Comparative Evaluation of LLMs for a Domain-Specific Pipeline Focused on Code Generation and Agentic RAG [Part 1]

![Comparative Evaluation of LLMs for a Domain-Specific Pipeline Focused on Code Generation and Agentic RAG [Part 1]](https://jbxeeb6ybylgemuz.public.blob.vercel-storage.com/main/public/white-paper/wp-thumb-26-tx5SbqWD2PbAM7bBOrWLutxhPYEYvh.png)
📖 Reading time: about 20 minutes
This article is the first part of a two-part series. Part 1 covers the research background, system architecture, and experimental design, while Part 2 covers the experimental results, pipeline optimization, and conclusions.
Introduction
Background and Motivation
The dramatic advancement of large language models (LLMs) is forcing a fundamental reconsideration of the paradigm of enterprise application design. In particular, the convergence of natural language processing, code generation, and information retrieval technologies has extended the potential of automation into enterprise domains such as payroll and HR management, where strict compliance with prescribed rules is essential.
Among these, payroll systems are domains that require a high degree of accuracy, with complex laws, tax calculations, and multilayered social insurance contribution rules intertwined. The Japanese payroll system in particular combines complex social insurance schemes such as employment insurance, health insurance, and employee pension insurance with year-end tax adjustment and special collection procedures for resident tax. As a result, practitioners must spend considerable human resources and time converting business rules written in natural language into system logic.
The subject of this study, "AI Check," adopts a three-stage pipeline to resolve these bottlenecks. In the first stage, natural-language payroll inspection perspectives are converted into SQL-form pseudocode. In the second stage, domain terms in the pseudocode are mapped to database field identifiers (MFIDs). In the third stage, the MFID-mapped pseudocode is converted into executable SQL queries. In this process, the LLM goes beyond simple text generation and performs both code generation and retrieval-augmented generation (RAG)-based agentic tasks.
Major vendors such as Anthropic's Claude, Google's Gemini, and OpenAI's GPT are currently competing to introduce enhanced inference modes branded as "Thinking" or "Reasoning." However, empirical comparative studies remain scarce on whether these high-performance modes are actually suitable for each task in real enterprise environments, especially within the multi-stage pipeline described above, and whether they contribute meaningful performance gains relative to cost.
Each stage of the pipeline requires different capabilities. If the code generation stage prioritizes syntactic accuracy and logical completeness above all else, the Agentic RAG stage depends fundamentally on the appropriateness of tool selection and the ability to interpret retrieval results. In addition, in production environments, not only quality scores but also cost efficiency and response stability, including empty-response and error control, act as decisive variables that determine the success or failure of the system.
Accordingly, this study uses a real Japanese payroll-system pipeline as a testbed and aims to quantitatively analyze performance differences across major LLM model configurations. It further seeks to identify models optimized for the characteristics of each task and to propose pipeline configuration strategies that can simultaneously achieve quality and cost efficiency.
Research Questions
This study aims to answer the following research questions.
RQ1. How do performance differences vary by LLM model family in code generation and Agentic RAG tasks?
We analyze the performance differences among the three model families—Claude, Gemini, and GPT—in natural language-to-pseudocode conversion (code generation) and term-to-MFID mapping (Agentic RAG) tasks. We compare them from multiple perspectives using traditional metrics such as BLEU, ROUGE-L, and BERT-F1, together with LLM-as-a-Judge-based evaluation and retrieval metrics such as Recall@K and MRR.
RQ2. What effect do Thinking/Reasoning modes have on performance in each task?
We analyze on a task-by-task basis whether the enhanced inference modes provided by each vendor—Claude's Extended Thinking, Gemini's Thinking, and GPT's Reasoning—actually improve performance in code generation and Agentic RAG tasks, or whether they instead degrade performance.
RQ3. How does model stability (empty-response rate) differ across models, and how does that affect model selection?
In real LLM operating environments, the frequency of empty responses and errors directly affects system reliability. We measure the empty-response rate of each model and analyze how practical model-selection criteria change when stability is considered together with quality scores.
RQ4. What is the optimal pipeline configuration when considering the cost-quality trade-off?
We analyze the cost-quality trade-off between using a single model across the entire pipeline and using mixed configurations in which different models are used at different stages. We derive optimal model combinations according to budget constraints and quality requirements, and identify Pareto-optimal configurations.
Contributions of the Study
The main contributions of this study can be summarized as follows.
First, we conducted a comparative evaluation of LLMs grounded in a real enterprise environment. Unlike prior research that relies on general benchmark datasets, this study systematically evaluates 13 LLM configurations (six Claude variants, four Gemini variants, and three GPT variants) on an actively used Japanese payroll-system pipeline, empirically comparing model performance on domain-specific tasks.
Second, we clarify the task-dependent effects of Thinking/Reasoning modes. Our analysis shows that Thinking modes do not guarantee universal performance improvements; instead, they produce conflicting effects depending on the task and the model. Claude models improved by +1.2 percentage points in code generation when Thinking mode was applied, but recorded a -6.6 percentage point decline in Agentic RAG, while GPT models showed the exact opposite pattern. These results suggest that indiscriminate application of Thinking modes can be counterproductive.
Third, we present a stability evaluation framework that goes beyond quality metrics. Unlike existing LLM evaluation studies that focus heavily on quality metrics, this study incorporates empty-response rate as a core evaluation criterion. GPT reasoning variants recorded empty-response rates of 21–23% in code-generation tasks, confirming that despite competitive quality scores, they are unsuitable for production deployment. This finding highlights the importance of stability metrics in LLM evaluation.
Fourth, we propose an optimized pipeline configuration capable of reducing cost by 60%. Compared with the conventional approach of using a single model across the entire pipeline, we show that strategically combining models suited to the characteristics of each stage can greatly reduce cost while maintaining comparable quality. We find that the optimal configuration uses the cost-efficient Gemini 3 Flash for code generation and the high-accuracy Claude Opus or GPT-5.2 (Think) for Agentic RAG.
Structure of the Paper
The rest of this paper is organized as follows.
Chapter 1, "Related Work," reviews prior research on LLM evaluation benchmarks, code generation, retrieval-augmented generation, LLM-as-a-Judge evaluation methodologies, and multi-agent systems.
Chapter 2, "System Architecture," describes the overall structure of AI Check and the role of each agent in this study. It covers the three-stage sequential processing structure of the natural language-to-pseudocode conversion agent and the RAG-based retrieval mechanism of the MFID mapping agent.
Chapter 3, "Experimental Design," explains the evaluated models, dataset composition, evaluation metrics, and cost-calculation method. It describes the characteristics of the code-generation dataset with 175 samples and the Agentic RAG dataset with 93 samples, and presents the LLM-as-a-Judge evaluation rubric in detail.
Experimental results, pipeline optimization, and conclusions from Chapter 4 onward are covered in Part 2.
Chapter 1. Related Work
This chapter reviews prior research on LLM evaluation benchmarks, LLM-based code generation, retrieval-augmented generation (RAG), LLM-as-a-Judge evaluation methodologies, and multi-agent systems.
LLM Evaluation Benchmarks
Benchmarks have been developed to objectively measure the performance of large language models. MMLU (Massive Multitask Language Understanding) is a representative benchmark that evaluates model knowledge and reasoning ability through multiple-choice questions spanning 57 subjects. Although it once had strong discriminative power between models, recent years have seen models achieve over 90% accuracy, leading to a saturation effect.
HELM (Holistic Evaluation of Language Models) is regarded as one of the most comprehensive academic benchmarks, applying seven evaluation dimensions—such as accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency—across 42 scenarios. BIG-Bench consists of 204 challenging tasks jointly designed by 442 researchers, covering multi-step reasoning, metaphor interpretation, theory of mind, and other tasks that probe the limits of current models.
In code generation, HumanEval has become the standard benchmark, and GSM8K is widely used to evaluate mathematical reasoning ability. More recently, benchmarks such as GPQA and SuperGPQA, which require doctoral-level knowledge, have appeared. Yet even these have seen high-performing models emerge within only about a year, revealing an accelerating trend of benchmark saturation.
To overcome the limitations of such static benchmarks, dynamic benchmarks such as LiveBench have been proposed. Dynamic benchmarks aim to address the problem of data contamination by continuously introducing new private data. Human-evaluation-based leaderboards such as Chatbot Arena and LLM-as-a-Judge approaches such as Alpaca Eval 2.0 and Arena Hard are also emerging as scalable evaluation methods.
LLM-Based Code Generation
Research on code generation using LLMs developed rapidly starting with OpenAI's Codex. Codex was trained on 159 GB of Python code collected from 54 million GitHub repositories and became the foundation of GitHub Copilot. Later, StarCoder added support for more than 80 programming languages, and Meta's CodeLlama was developed by fine-tuning Llama 2 on a code-specialized dataset.
Recent studies have analyzed the limitations of LLM-based code generation in greater depth. "Where Do LLMs Still Struggle?" (2025) analyzed failure patterns of major models such as Claude Sonnet-4, DeepSeek-V3, and GPT-4o on the MBPP, HumanEval, BigCodeBench, and LiveCodeBench benchmarks, revealing that static complexity and prompt misinterpretation are recurring weaknesses.
LLM use is also active in the text-to-SQL field. Benchmarks such as Spider and WikiSQL are used as standards, and in recent years, research has expanded into domain-specific code generation and low-resource languages. Research that converts rules from specific domains such as payroll and accounting systems into code forms a distinct area of study because it simultaneously requires domain knowledge and code-generation capability.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) has emerged as an approach for mitigating LLM hallucinations and enabling access to up-to-date information. RAG works by first retrieving relevant documents for a user's question, then providing the retrieved context to the LLM to generate a response.
The comprehensive survey by Gupta et al. systematically organizes RAG architectures, retrieval-generation integration methods, scalability and bias issues, and future directions. More recently, Agentic RAG has emerged as a new paradigm that goes beyond simple retrieval-generation pipelines. In Agentic RAG, an LLM agent actively searches for and verifies information using tools, overcoming the limitations of passive retrieval in conventional RAG.
Jayavardhana et al. (2025) proposed an Agentic RAG system combining a BERT-based cross-encoder and GPT-4, improving factual accuracy in the academic-advising domain. QuIM-RAG introduced a new retrieval mechanism based on question-to-question inverted-index matching, improving reasoning performance in multi-hop question answering.
Evaluation of RAG systems commonly uses retrieval metrics such as Recall@K, MRR (Mean Reciprocal Rank), and precision, as well as measures such as hallucination reduction rate and factual accuracy. Nguyen et al. (2024) reported that applying RAG increased Llama-3 accuracy from 57.50% to 81.50%, and GPT-4-turbo to 91.92%, demonstrating the effectiveness of RAG.
LLM-as-a-Judge Evaluation Methodology
Traditional evaluation metrics for natural language generation (NLG) include BLEU, ROUGE, and BERTScore. BLEU (Bilingual Evaluation Understudy) measures agreement between generated text and reference text based on n-gram precision, with a brevity penalty applied to correct bias toward short outputs. ROUGE-L evaluates structural similarity using the longest common subsequence (LCS) and is widely used in summarization tasks. BERTScore measures semantic similarity using contextual embeddings from BERT and has been shown to correlate more strongly with human judgment than n-gram-based metrics.
These traditional metrics have limitations in capturing semantic equivalence in code generation and complex reasoning tasks. In response, the LLM-as-a-Judge paradigm has emerged as a new evaluation method. LLM-as-a-Judge uses a strong LLM such as GPT-4 or Claude as an evaluator to assess the quality of generated outputs.
"LLMs-as-Judges: A Comprehensive Survey" (2024) systematically organizes the functionality, methodology, applications, meta-evaluation, and limitations of this paradigm. Major advantages of LLM-as-a-Judge include interpretability through natural-language output, generalization across tasks, and scalability for large-scale evaluation.
Bias issues in LLM evaluators have also been pointed out. Position bias, model-preference bias, and variability depending on prompt design can all undermine reproducibility. To mitigate these issues, researchers recommend providing task-specific reference answers, using ensemble methods, applying Chain-of-Thought (CoT) prompting, and designing detailed evaluation rubrics.
In this study, we apply the LLM-as-a-Judge approach to evaluate code-generation quality across four dimensions—Syntactic Correctness, Semantic Equivalence, Condition Completeness, and Structural Similarity—using a 5-point scale for each, for a total of 20 points. By providing a detailed scoring rubric for each dimension, we aim to ensure consistency and reproducibility in evaluation.
Multi-Agent Systems and Pipelines
LLM-based multi-agent systems (MAS) are an approach to solving complex problems through collaboration among multiple agents. The ReAct framework enabled agents to perform tasks using tools by alternating between reasoning and acting. Later, agent frameworks such as AutoGPT and LangChain Agents emerged, enabling practical applications.
"Large Language Model Based Multi-agents: A Survey of Progress" (IJCAI, 2024) comprehensively summarizes the development of LLM-based multi-agent systems. The survey covers agent profiling, communication methods, skill development, and applications in planning and reasoning, analyzing the evolutionary path from single-agent to multi-agent systems.
MegaAgent (ACL Findings, 2025) proposed a system that autonomously generates up to 590 agents without predefined standard operating procedures (SOPs) and performs complex tasks such as software development and social simulation. The system achieves coordination among agents through memory retrieval and task decomposition using a vector database.
The system studied here adopts a sequential-agent structure. Inside the natural language-to-pseudocode conversion agent, a structure analyzer, condition analyzer, and pseudocode creator are executed sequentially, with each stage's output passed as the input to the next stage. The MFID mapping agent is invoked using an AgentTool approach and performs RAG-based retrieval for each term. In this pipeline structure, selecting a model suited to each stage has a critical impact on overall system performance.
Research Gaps and Positioning of This Study
A review of the literature reveals the following research gaps.
First, there is a lack of research on model selection in multi-stage pipelines. Most LLM evaluation studies focus on comparing models for a single task, while research on strategies that use different models at different stages within a pipeline remains limited.
Second, there is a lack of task-specific analysis of the effects of Thinking/Reasoning modes. Although each provider offers enhanced reasoning modes, there is limited systematic analysis of which tasks these modes are actually effective for.
Third, stability metrics remain underdeveloped. Existing evaluation studies tend to focus on quality metrics while overlooking practical stability metrics such as empty-response rates and error rates, which are important in real operating environments.
Fourth, there is no integrated evaluation of domain-specific code generation and Agentic RAG. In specific domains such as payroll systems, we found no prior evaluation studies of pipelines that integrate both code generation and RAG.
To address these gaps, this study conducts a comprehensive comparative evaluation of models for code generation and Agentic RAG tasks using a real Japanese payroll-system pipeline, and proposes an optimal pipeline configuration strategy by analyzing both the task-specific effects of Thinking modes and stability metrics.
Chapter 2. System Architecture
This chapter describes the overall structure of AI Check and the role of each component in detail. We first introduce the system overview and pipeline structure, and then explain the operating mechanisms of the two core agents evaluated in this study—the natural language-to-pseudocode conversion agent and the MFID mapping agent.
System Overview
AI Check is a system that automatically converts payroll inspection perspectives written by payroll administrators in natural language (Japanese) into executable SQL queries. The system enables users to describe inspection conditions in natural language, without needing to know complex SQL syntax, and then retrieves from the database the subjects who match those conditions.
A typical text-to-SQL approach converts natural language directly into SQL, but the target database in this system has a large-scale schema consisting of more than 300 tables and more than 1,350 columns. In addition, column names are expressed as internal codes (MFIDs) such as FPPAR03 and FRPAP15, making it difficult for an LLM to generate accurate SQL directly from natural language. To address this complexity, the system separates the problem into three stages.
Specifically, it (1) converts natural language into pseudocode containing domain terms, (2) maps the domain terms in the pseudocode to MFIDs based on vector similarity search, and then (3) converts the MFID-mapped pseudocode into executable SQL.
As shown in Figure 1, the system adopts a multi-stage pipeline composed of three main agents.
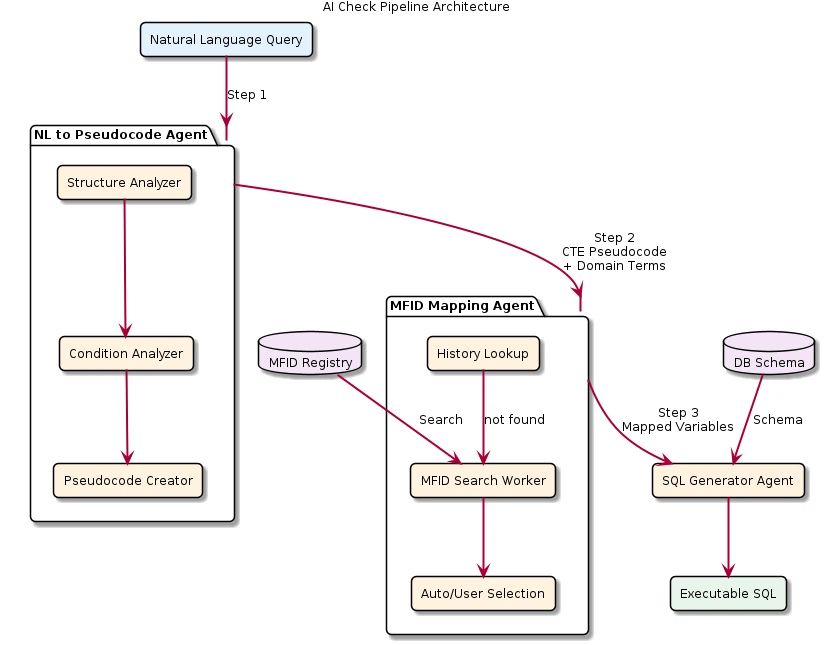
Figure 1: AI Check pipeline structure
NL to Pseudocode Agent converts payroll inspection conditions written in natural language into SQL-like pseudocode. At this stage, the LLM's code-generation capability is used as the core mechanism.
MFID Mapping Agent maps domain terms included in the pseudocode (e.g., "Employment Date," "Fixed Component Start Date") to actual database field identifiers (MFIDs). At this stage, a vector-retrieval-based Agentic RAG approach is used.
Query Translation Agent converts MFID-mapped pseudocode into the final executable SQL query. Because this stage is driven primarily by relatively rule-based transformations, it was excluded from the evaluation scope of this study.
In this study, we selected the NL to Pseudocode Agent and the MFID Mapping Agent as evaluation targets because LLM capability directly affects system performance in these stages.
NL to Pseudocode Agent
Overview
The NL to Pseudocode Agent is responsible for converting payroll inspection perspectives written in natural language into SQL-like pseudocode. Because it must accurately express complex business rules in the Japanese payroll system—such as employment insurance, health insurance, employee pension insurance, and year-end tax adjustment—as code, it requires both domain understanding and code-generation capability from the LLM.
Three-Stage Sequential Processing Structure
Rather than using a single LLM call, this agent adopts a structure in which three sub-agents run sequentially. Figure 2 shows the processing flow of these three stages.
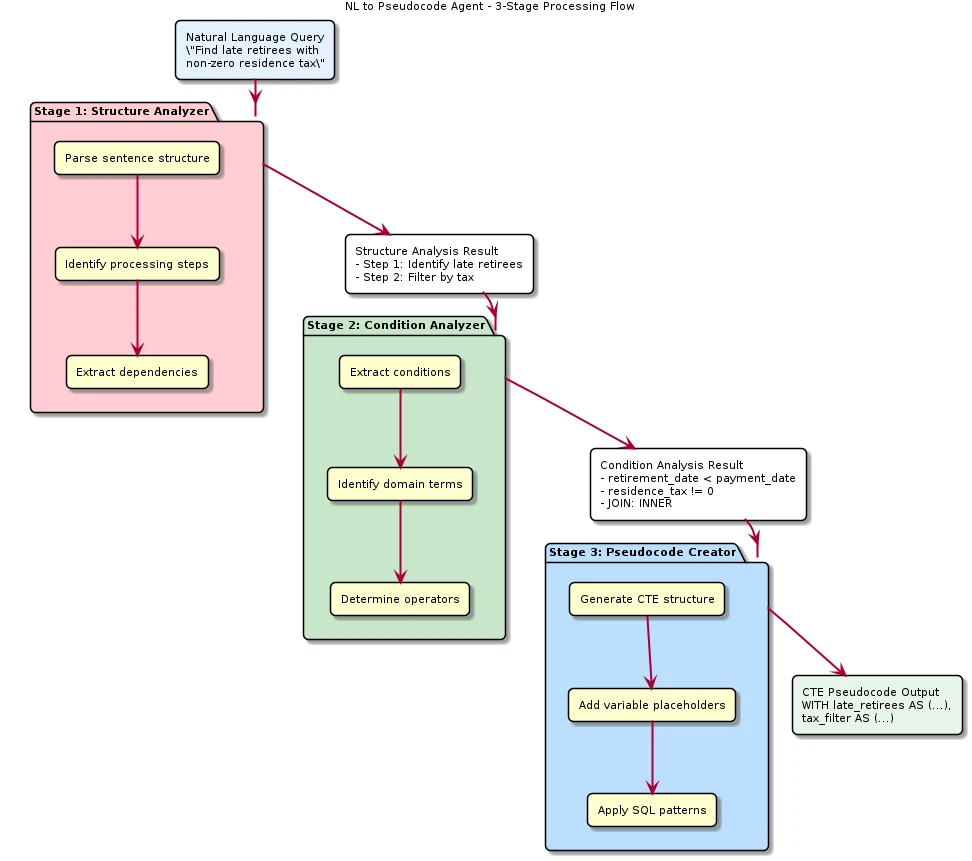
Figure 2: NL to Pseudocode Agent — three-stage processing flow
Each stage takes the output of the previous stage as input and performs the transformation incrementally.
(1) Structure Analyzer
- Extracts the hierarchical structure of subject concepts from the natural-language input
- Applies different processing algorithms depending on the mode (trigger/anomaly/free)
- trigger mode: identifies the hierarchical relationship between the top-level subject concept and lower-level subject concepts, and recognizes combination relations such as UNION ALL
- anomaly mode: identifies execution order (1., 2., ...) and assigns an appropriate concept name to the processing of each step
- Output format: structured definitions in the form of "concept name" = "natural-language definition"
(2) Condition Analyzer
- Converts structured natural-language definitions into SQL pseudocode conditions
- Constructs SELECT, FROM, and WHERE clauses in pseudocode form
- Main transformation rules:
- All item names are written in Japanese (except system-required fields)
- Null check for numeric columns:
COALESCE(column_name, '0') = '0' - Null check for string columns:
COALESCE(column_name, '') = '' - Conversion of logical operators: "and" → AND, "or" → OR
- Subset chain principle: if concept B depends on concept A, concept A must always be referenced in the FROM clause
(3) Pseudocode Creator
- Syntactically transforms SQL pseudocode conditions into CTE (Common Table Expression) form
- Does not change the content of the conditions at all, and only organizes syntactic style such as indentation, line breaks, and placement of AS clauses
- Final output: readable, structured pseudocode in CTE form
Input/Output Example
Table 1 shows an actual input/output example for the NL to Pseudocode Agent.

Table 1: NL to Pseudocode Agent input/output example
Below is an example of input and output processed by the actual system.
Input (natural language)
前月Payprocessに存在せず、当月Payprocessで初めて計算対象となった人(これを「入社者」とする)。
入社者の中から、固定部開始日と勤怠部開始日のうちより古い日付よりも前の退職年月日が登録されている人を過去退職者として特定する。入社者から過去退職者を除外した後、次のように分類する:
- 入社年月日が固定部開始日から固定部終了日の期間に含まれる場合 ⇒ 新規入社として処理
- 入社年月日が固定部開始日より前の場合 ⇒ 新規遅れ入社として処理
(1) Structure Analyzer output — extracting the hierarchical structure
- 入社者 = 前月Payprocessに存在せず、当月Payprocessで初めて計算対象となった人
- 過去退職者 = 入社者のうち、固定部開始日と勤怠部開始日のうちより古い日付よりも前の退職年月日が登録されている人
- 新規入社 = 入社者から過去退職者を除外した人のうち、入社年月日が固定部開始日から固定部終了日の期間に含まれる人
- 新規遅れ入社 = 入社者から過去退職者を除外した人のうち、入社年月日が固定部開始日よりも前の人
(2) Condition Analyzer output — SQL condition transformation
- 入社者 = SELECT payer_id, ..., 入社年月日, 固定部開始日, 固定部終了日, 勤怠部開始日, 退職年月日
FROM employee
WHERE pay_process = $当月Payprocess$
AND cal_process = $当月Payprocess$
AND (payer_id, pay_number) NOT IN (SELECT payer_id, pay_number FROM employee_prev);
- 過去退職者 = SELECT ... FROM 入社者
WHERE COALESCE(退職年月日, '') != ''
AND 退職年月日 < CASE WHEN 固定部開始日 < 勤怠部開始日
THEN 固定部開始日 ELSE 勤怠部開始日 END;
- 新規入社 = SELECT ..., '新規入社' as 入社種別 FROM 入社者
WHERE (payer_id, pay_number) NOT IN (SELECT payer_id, pay_number FROM 過去退職者)
AND 入社年月日 BETWEEN 固定部開始日 AND 固定部終了日;
- 新規遅れ入社 = SELECT ..., '新規遅れ入社' as 入社種別 FROM 入社者
WHERE (payer_id, pay_number) NOT IN (SELECT payer_id, pay_number FROM 過去退職者)
AND 入社年月日 < 固定部開始日;
(3) Pseudocode Creator output — conversion into CTE form
入社者 AS (
SELECT payer_id, calcu_labor_id, pay_number, emp_number,
pay_process, cal_process, 入社年月日, 固定部開始日,
固定部終了日, 勤怠部開始日, 退職年月日
FROM employee
WHERE pay_process = $当月Payprocess$
AND cal_process = $当月Payprocess$
AND (payer_id, pay_number) NOT IN
(SELECT payer_id, pay_number FROM employee_prev)),
過去退職者 AS (
SELECT payer_id, calcu_labor_id, pay_number, emp_number,
pay_process, cal_process, 入社年月日, 固定部開始日,
固定部終了日, 勤怠部開始日, 退職年月日
FROM 入社者
WHERE COALESCE(退職年月日, '') != ''
AND 退職年月日 < CASE
WHEN 固定部開始日 < 勤怠部開始日 THEN 固定部開始日
ELSE 勤怠部開始日 END),
新規入社 AS (
SELECT *, '新規入社' as 入社種別
FROM 入社者
WHERE (payer_id, pay_number) NOT IN
(SELECT payer_id, pay_number FROM 過去退職者)
AND 入社年月日 BETWEEN 固定部開始日 AND 固定部終了日),
新規遅れ入社 AS (
SELECT *, '新規遅れ入社' as 入社種別
FROM 入社者
WHERE (payer_id, pay_number) NOT IN
(SELECT payer_id, pay_number FROM 過去退職者)
AND 入社年月日 < 固定部開始日)
The generated pseudocode has the following characteristics.
- CTE-based structure: progressively filters subjects using CTEs in the WITH clause
- Japanese-SQL hybrid: combines Japanese table and column names with SQL syntax
- Logical hierarchy: a logical flow that proceeds from 入社者 → 過去退職者 → 新規入社/新規遅れ入社
MFID Mapping Agent
Overview
The MFID Mapping Agent is responsible for mapping domain terms contained in the pseudocode to actual database field identifiers (MFIDs, Master Field IDs). The payroll-system database contains thousands of fields, and expressions that refer to the same concept (e.g., "Date of Employment" and "Employment Date") must be mapped accurately to the correct MFID.
MFID Data Structure
An MFID is an identifier that uniquely identifies each field in the payroll-system database and is managed together with the following metadata.

Table 2: MFID metadata structure
Vector Retrieval Infrastructure
For MFID mapping, the system adopts a RAG architecture based on vector similarity retrieval.
Vector database: PostgreSQL + pgvector extension is used. pgvector is an open-source extension that adds vector similarity search functionality to PostgreSQL, with the advantage of easy integration with existing relational databases and low operational complexity.
Embedding model: Google's Gemini Embedding model (gemini-embedding-001, 2000 dimensions) is used. In selecting the embedding model, we comparatively evaluated the following four models.
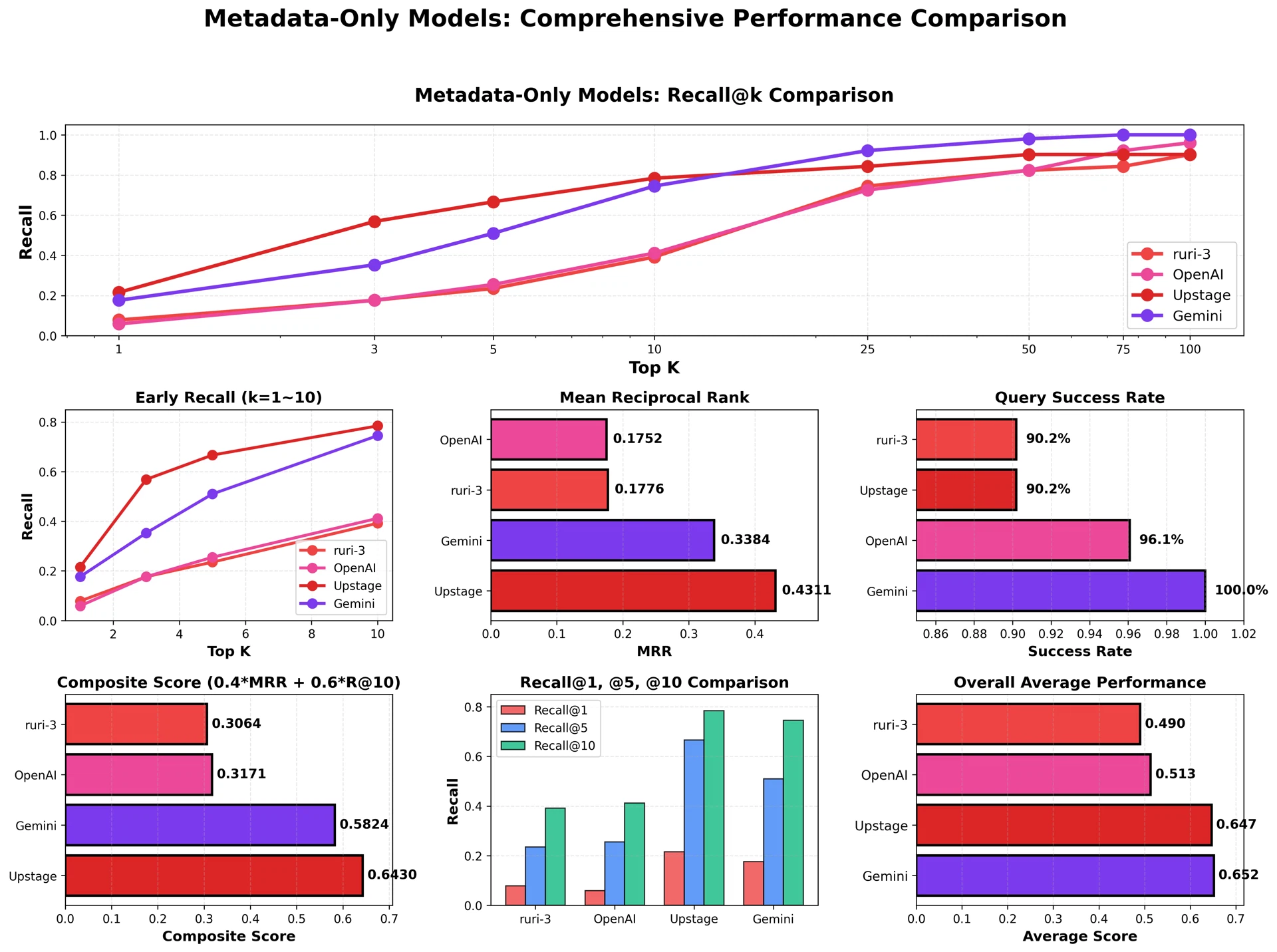
Figure 3: Evaluation by embedding model — Composite Score = 0.4 × MRR + 0.6 × Recall@10
As a result of the evaluation, Upstage Solar ranked first by Composite Score, but because its API was still in beta and its stability could not be guaranteed, it was unsuitable for production use. Gemini Embedding, which showed the best Recall@10 performance (80.4%) and had a stable API, was ultimately selected.
How Agentic RAG Operates
The MFID Mapping Agent does not operate as a simple retrieval-generation pipeline, but rather as an Agentic RAG system. Figure 4 shows the overall flow of this agent.
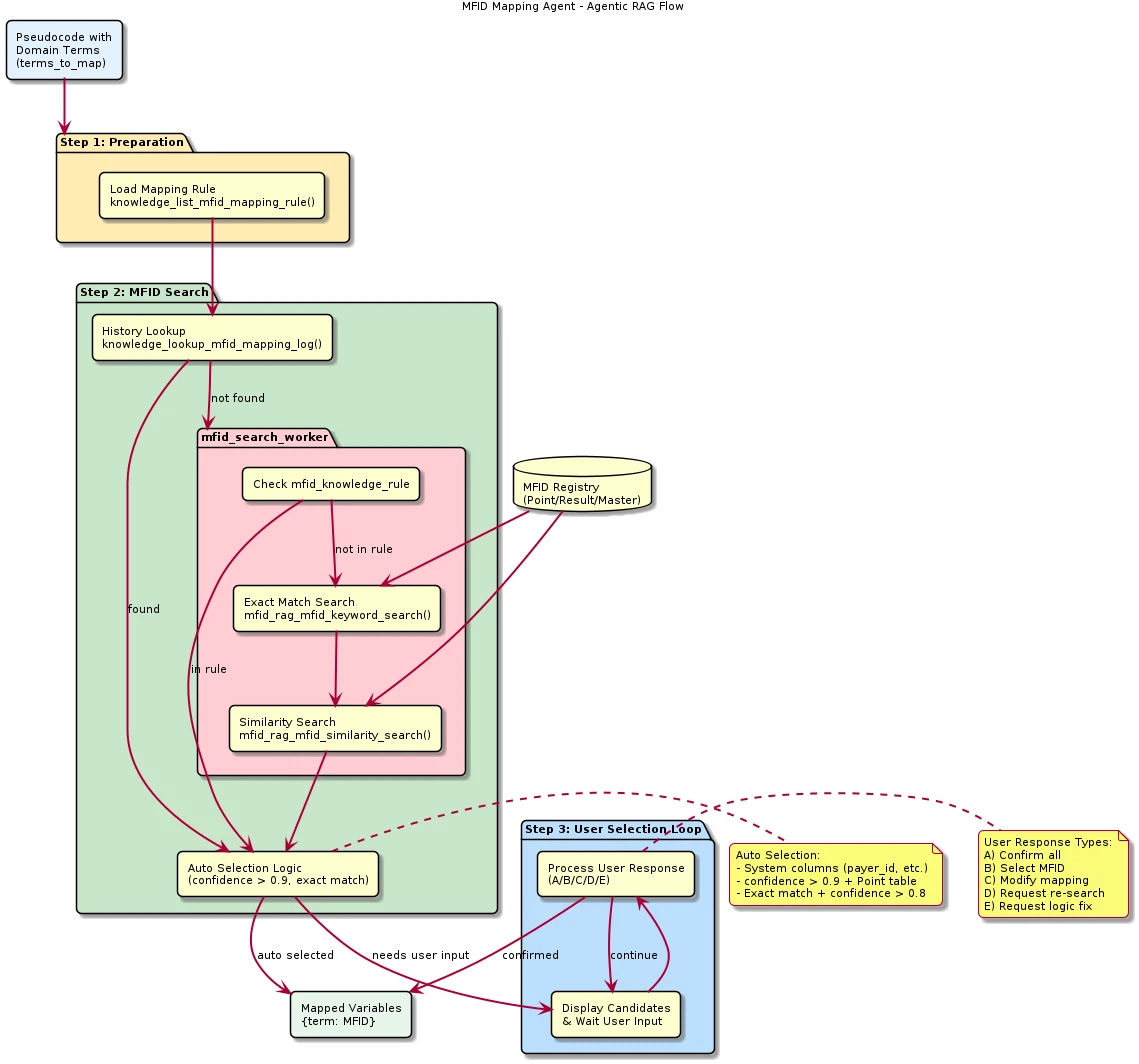
Figure 4: MFID Mapping Agent — Agentic RAG flow
The LLM agent actively calls tools to retrieve the information it needs, interprets the retrieval results, and determines the optimal mapping.
The core characteristics of this approach are as follows.
- Parallel tool calls: retrieval for multiple terms is executed in parallel to reduce processing time
- Context-aware selection: selection considers context such as category and payroll type, rather than relying only on similarity ranking
- Adaptive retrieval: additional retrieval can be performed when the first search results are insufficient
Evaluation Targets and Scope
In this study, we selected the NL to Pseudocode Agent and the MFID Mapping Agent as evaluation targets for the following two reasons.
First, these are stages with high LLM dependence. Both agents depend heavily on the LLM's language understanding, reasoning, and generation capabilities. In contrast, the Query Translation Agent is primarily rule-based, so performance differences caused by LLM selection are relatively small.
Second, these tasks have different task characteristics. The NL to Pseudocode Agent is a code-generation task that requires converting natural language into structured pseudocode. The MFID Mapping Agent is an Agentic RAG task that requires tool use and interpretation of retrieval results. These different task characteristics suggest that even the same LLM may perform differently across stages, raising the need for model selection optimized for each stage.

Table 3: Comparison of evaluated task characteristics
Summary
This chapter explained the overall pipeline structure of AI Check and each of its components. The system consists of three stages—NL to Pseudocode Agent, MFID Mapping Agent, and Query Translation Agent—and in this study we selected the first two stages for evaluation because they are highly dependent on LLMs and differ in task characteristics.
The NL to Pseudocode Agent converts natural language into CTE-based pseudocode through a three-stage sequential structure consisting of structure_analyzer, condition_analyzer, and pseudocode_creator. The MFID Mapping Agent maps domain terms to MFIDs through an Agentic RAG approach using pgvector-based vector retrieval and the Gemini Embedding model.
The next chapter details the experimental design for evaluating these two tasks, including the evaluated models, dataset composition, and evaluation metrics.
Chapter 3. Experimental Design
This chapter describes the experimental design for comparative LLM evaluation in detail. It explains the evaluated models, dataset composition, evaluation metrics, and the methods used to measure cost and performance.
Evaluated Models
This study selected 13 model configurations from the three major LLM providers—Anthropic, Google, and OpenAI—as evaluation targets. Alongside their base models, each provider supports Thinking/Reasoning modes that offer enhanced inference capability, and this study includes both modes in the evaluation.
Claude Family (Anthropic)
Anthropic's Claude 4.5 series consists of three tiers—Haiku, Sonnet, and Opus—each offering a different speed-cost-quality trade-off. Extended Thinking mode is a feature that allows the model to think more deeply on complex reasoning tasks.

Table 4: Claude family models
Gemini Family (Google)
Google's Gemini series is divided into Flash and Pro tiers, where Flash targets fast response speed and Pro targets higher quality. Thinking mode is a feature that explicitly executes the reasoning process.

Table 5: Gemini family models
GPT Family (OpenAI)
OpenAI's GPT series consists of 5.2 and 5 Mini. Reasoning mode (the o1 series) is designed to perform step-by-step thinking on complex reasoning problems.
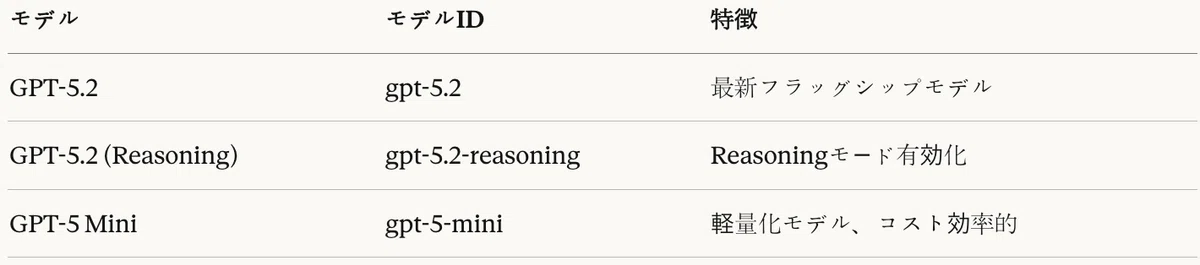
Table 6: GPT family models
Summary of Model Configurations
Table 7 summarizes all evaluated models. The 13 configurations consist of six Claude variants, four Gemini variants, and three GPT variants.

Table 7: Summary of evaluated models
Dataset Composition
This study constructed separate datasets for the two tasks.
Code Generation Dataset (CodeGen)
To evaluate the code-generation task, we collected 175 payroll inspection perspectives used in the actual AI Check system. Each sample consists of a natural-language input (Japanese) and the correct pseudocode (reference).

Table 8: Code-generation dataset characteristics
The dataset includes payroll-system inspection scenarios such as the following.
- Joiners / leavers processing (join, leave)
- Social insurance qualification acquisition / loss (qualification acquisition, qualification loss)
- Payroll calculation anomaly detection (payroll calculation anomalies)
- Year-end tax adjustment-related inspections (year-end tax adjustment)
Agentic RAG Dataset (MFID Mapping)
To evaluate the Agentic RAG task, we constructed 93 domain-term-to-MFID mapping samples. Each sample consists of a term extracted from pseudocode and the correct MFID.
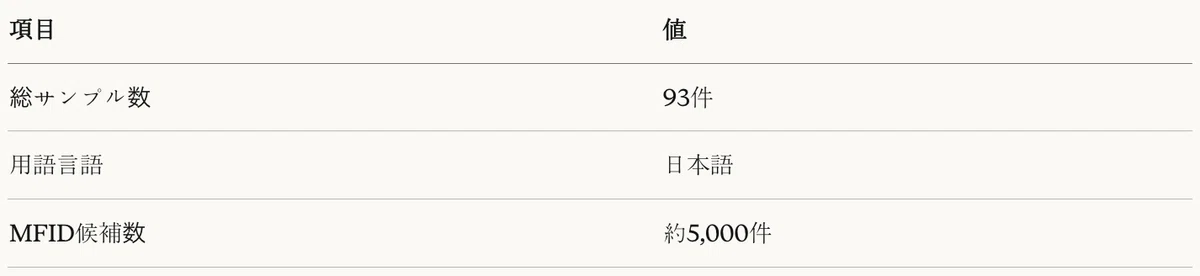
Table 9: Agentic RAG dataset characteristics
Evaluation Metrics
Evaluation Metrics for the Code Generation Task
For the code-generation task, we used both traditional text-similarity metrics and LLM-as-a-Judge-based evaluation.
Traditional text metrics
BLEU (Bilingual Evaluation Understudy)
BLEU measures the agreement between generated text and reference text based on n-gram precision.
BLEU = BP × exp(Σ wₙ log pₙ)
Here, N is the maximum n-gram order (typically 4), wₙ = 1/N is the uniform weight, and pₙ is the modified n-gram precision. The brevity penalty is defined as 1 when c > r, and e^(1-r/c) when c ≤ r. (c: candidate text length, r: reference text length)
ROUGE-L (Longest Common Subsequence)
ROUGE-L calculates the F1 score based on the longest common subsequence (LCS).
ROUGE-L = (1 + β²) × R_LCS × P_LCS / (R_LCS + β² × P_LCS)
BERT-F1 (BERTScore)
BERTScore measures semantic similarity based on cosine similarity of BERT embeddings.
F_BERT = 2 × (P_BERT × R_BERT) / (P_BERT + R_BERT)
LLM-as-a-Judge evaluation
To complement the limitations of traditional metrics, we applied an LLM-as-a-Judge approach. GPT-4 was used as the evaluator, and outputs were scored out of 5 points each across four dimensions, for a total of 20 points.
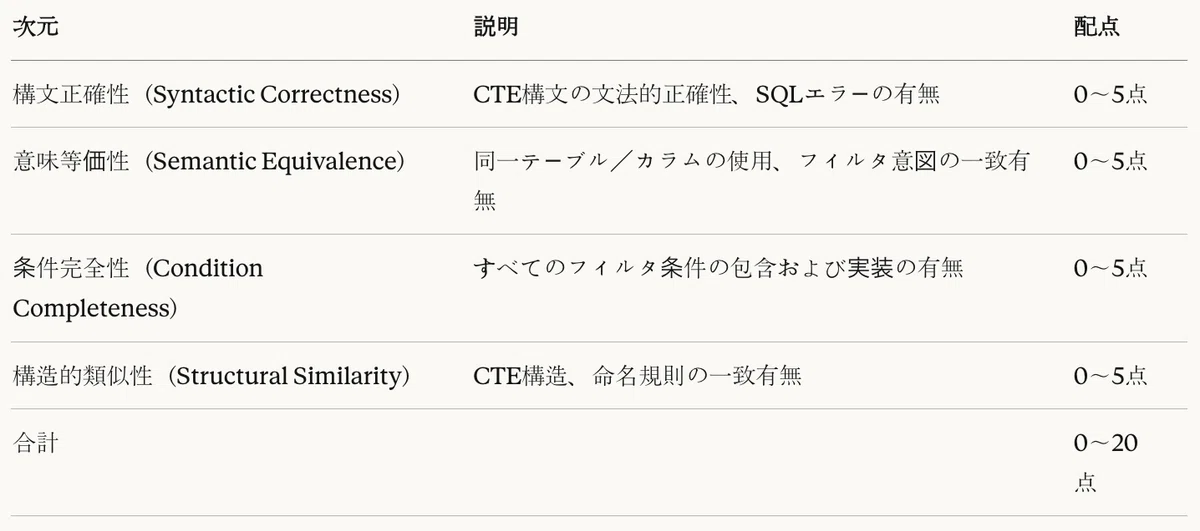
Table 10: LLM-as-a-Judge evaluation criteria
Evaluation Metrics for the Agentic RAG Task
For the Agentic RAG task, we applied standard metrics from the field of information retrieval.
Recall@K
Recall@K measures the inclusion rate of the correct answer within the top-K retrieval results.
Recall@K = |relevant items ∩ top-K items| / |relevant items|
MRR (Mean Reciprocal Rank)
MRR measures the mean reciprocal of the rank position of the correct answer.
MRR = (1/|Q|) × Σ (1/rank_q)
Metric Normalization
All metrics were normalized to a 0–100% scale to enable comparison.
- BLEU, ROUGE-L, BERT-F1: original 0–1 range → ×100 (%)
- Individual LLM-as-a-Judge scores: 0–5 range → ×20 (%)
- Total LLM-as-a-Judge score: 0–20 range → ×5 (%)
- Recall@K, MRR: original 0–1 range → ×100 (%)
Cost and Performance Indicators
Token Pricing
Costs were calculated based on the API pricing policies of each provider. Table 11 shows the USD price per 1M (one million) tokens.
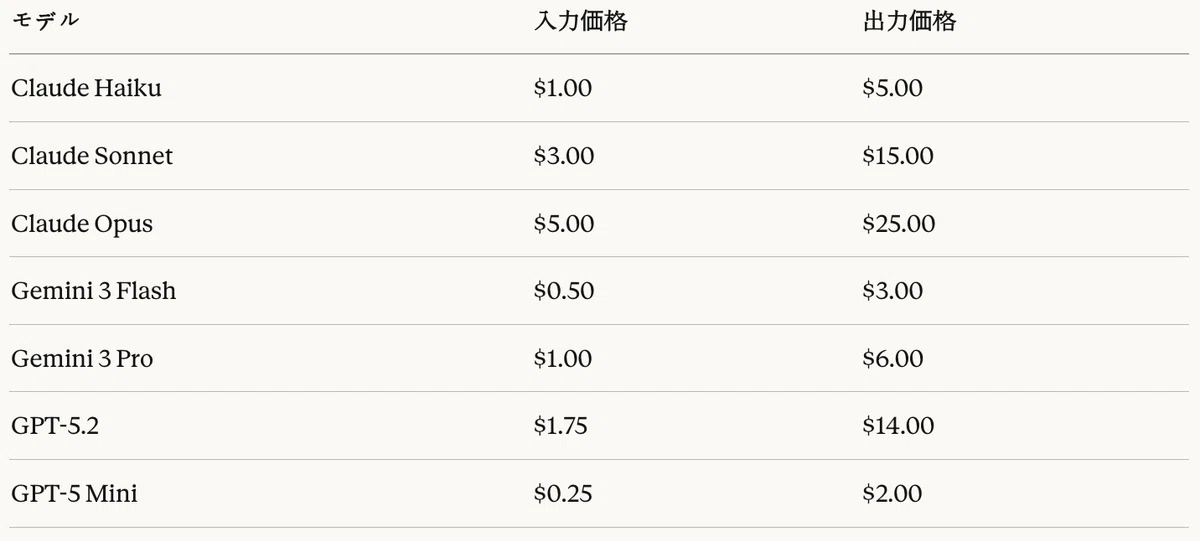
Table 11: Token pricing by model (USD per 1M tokens)
Cost-Efficiency Metric
To consider quality and cost simultaneously, we defined a cost-efficiency metric.
Cost efficiency = quality score / cost
- Code generation: total LLM-as-a-Judge score (%) / cost per 1K requests ($)
- Agentic RAG: MRR (%) / cost per 1K requests ($)
Experimental Environment and Settings
Experimental Environment
- API calls: official APIs from each provider were used
- Parallel processing: requests were executed in parallel within the allowed concurrent-request limit
- Retry policy: up to 3 retries on API errors
- Timeout: maximum 120 seconds per request
Model Settings
Consistent settings were applied to all models.

Table 12: Model settings
For Think/Reasoning modes, we followed each provider's recommended settings.
- Claude Extended Thinking: applied a thinking budget
- Gemini Thinking: enabled the thinking parameter
- GPT Reasoning: reasoning_effort = "high"
Summary
This chapter described the experimental design for comparative LLM evaluation in detail. The evaluation covers 13 model configurations (six Claude variants, four Gemini variants, and three GPT variants) on a code-generation dataset of 175 items and an Agentic RAG dataset of 93 items.
For evaluation metrics, the code-generation task uses traditional metrics—BLEU, ROUGE-L, and BERT-F1—together with four-dimensional LLM-as-a-Judge evaluation, while the Agentic RAG task uses Recall@K and MRR. For cost analysis, we calculate the cost per 1K requests based on each provider's token pricing and analyze the trade-off between quality and cost through a cost-efficiency metric.
The next chapter analyzes the experimental results for the code-generation task in detail.
📖 Part 2 covers the detailed experimental results for the 13 models (code generation and Agentic RAG), analysis of the impact of Thinking modes, stability evaluation, the cost-quality trade-off, and the optimal pipeline configuration strategy.
🚀 Try QueryPie AI now