Comparative Evaluation of LLMs for a Domain-Specific Pipeline Focused on Code Generation and Agentic RAG [Part 2]

![Comparative Evaluation of LLMs for a Domain-Specific Pipeline Focused on Code Generation and Agentic RAG [Part 2]](https://jbxeeb6ybylgemuz.public.blob.vercel-storage.com/main/public/white-paper/wp-thumb-27-3sETyUsSvKZAuVBDP7LBipEDALd7uq.png)
📖 Reading time: about 25 minutes
This article is the second part of a two-part series. For the research background, system architecture, and experimental design, please refer to Part 1. Part 2 covers the experimental results, pipeline optimization, and conclusions.
Chapter 4. Experimental Results: Code Generation Task
This chapter presents the evaluation results for the code generation task of the NL to Pseudocode Agent. We analyze the results of both traditional text metrics and LLM-as-a-Judge evaluation, and examine the impact of Think mode and model stability.
Overall Quality Evaluation Results
Traditional Text Metrics
Table 13 summarizes the results of traditional text metrics for the major models.
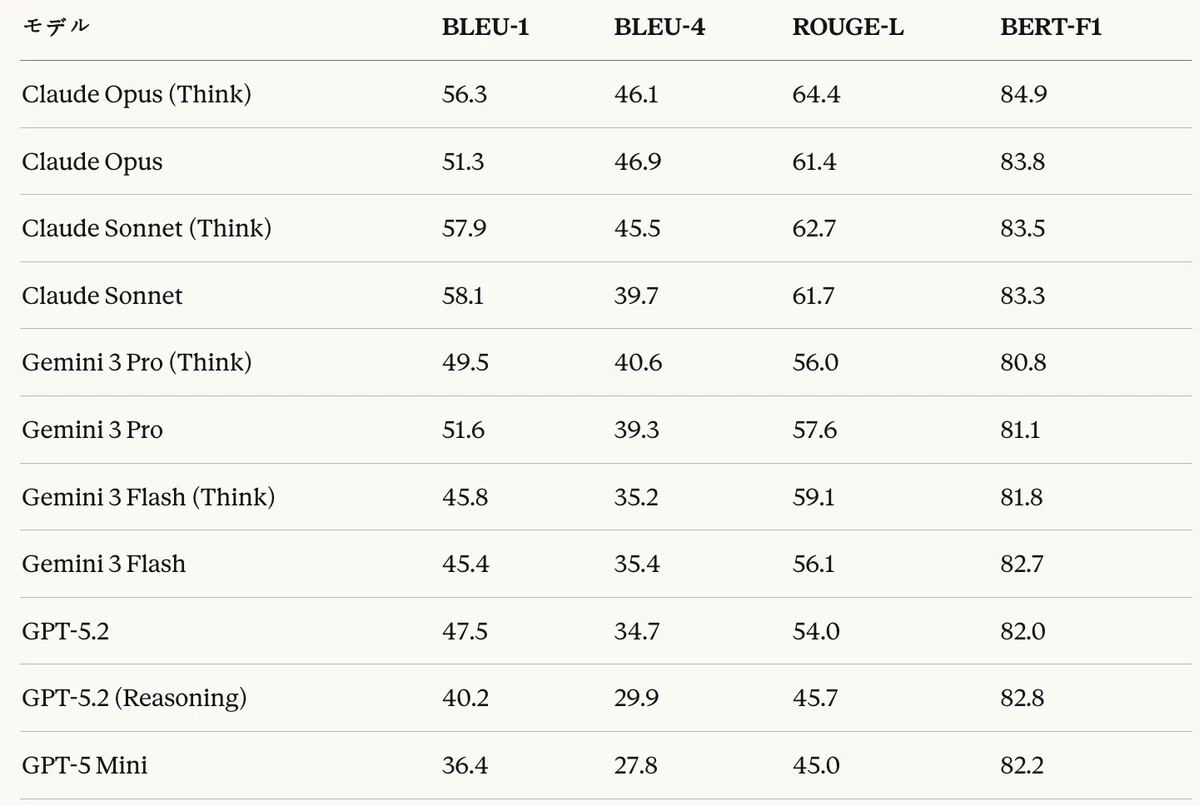
Table 13: Code generation task — traditional text metric results (%)
Claude models recorded strong performance on traditional metrics. In ROUGE-L, Claude Opus (Think) achieved the highest score at 64.4%, and in BERT-F1, Claude Opus (Think) also ranked first at 84.9%. GPT models showed relatively low scores in BLEU and ROUGE-L, but maintained a level comparable to other models in BERT-F1.
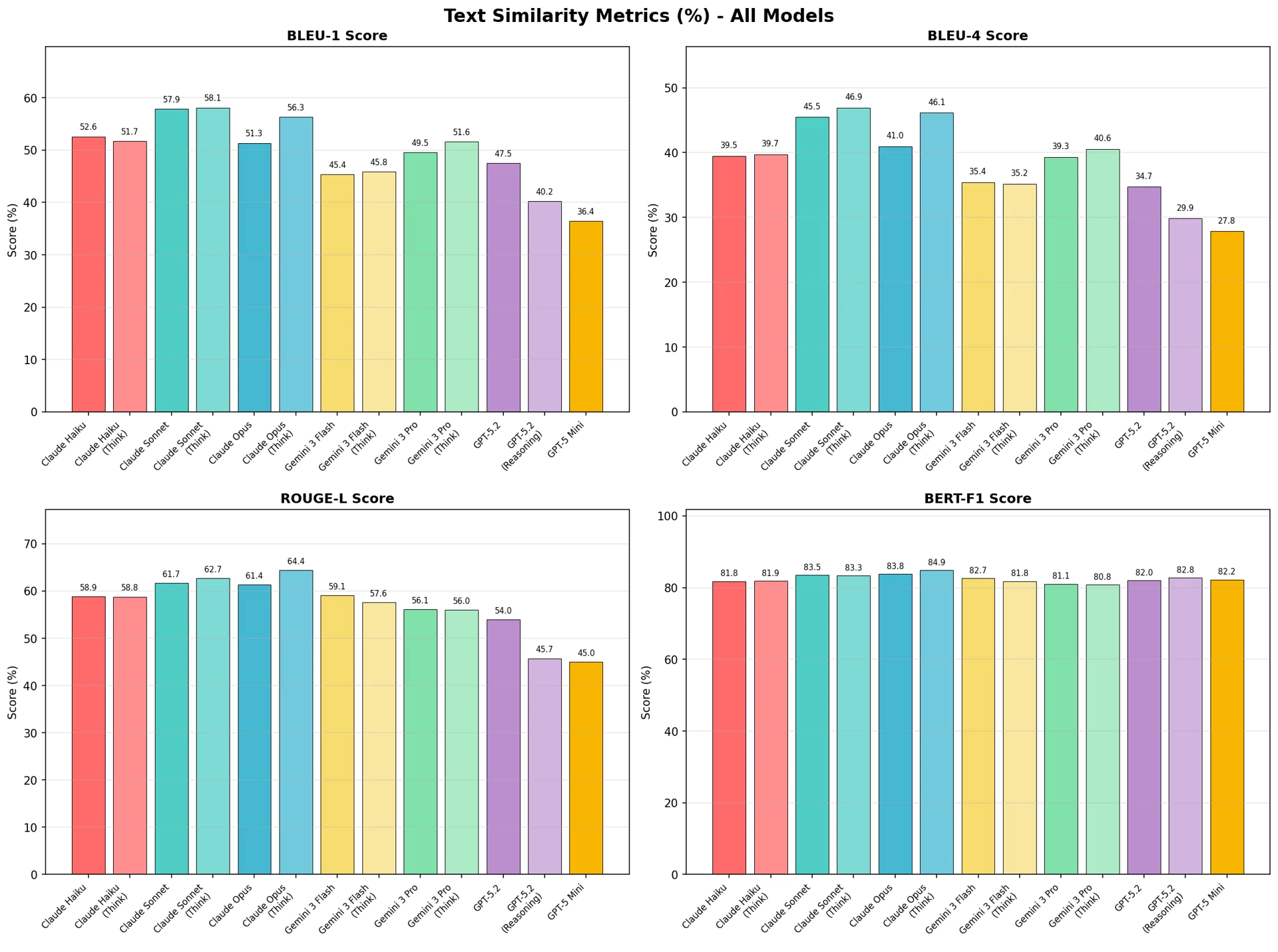
Figure 5: Text similarity metrics (%) — comparison across all models
LLM-as-a-Judge Evaluation Results
Table 14 organizes the LLM-as-a-Judge evaluation results.
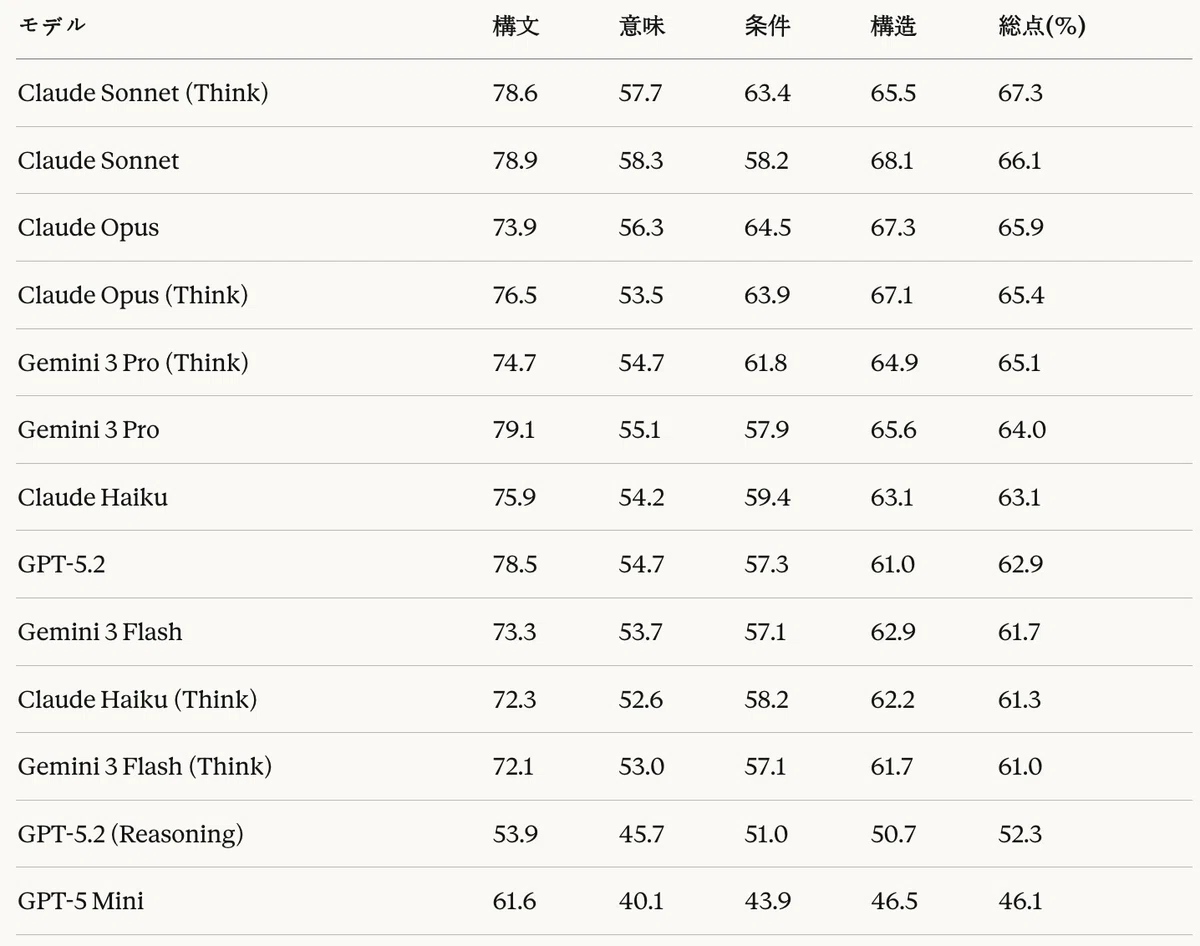
Table 14: Code generation task — LLM-as-a-Judge evaluation results (normalized %)
In the LLM-as-a-Judge evaluation, Claude Sonnet (Think) ranked first with 67.3%, followed by Claude Opus in second place with 66.1%. Among cost-efficient models, Gemini 3 Flash recorded 61.7%.
Looking at the results by dimension, all models recorded high scores in syntactic correctness (53.9–79.1%), while semantic equivalence and condition completeness remained at a moderate level (40.1–58.3%). This suggests that the models are proficient at generating grammatically correct CTE syntax, but still have limitations in capturing the exact meaning and conditions of the reference code.
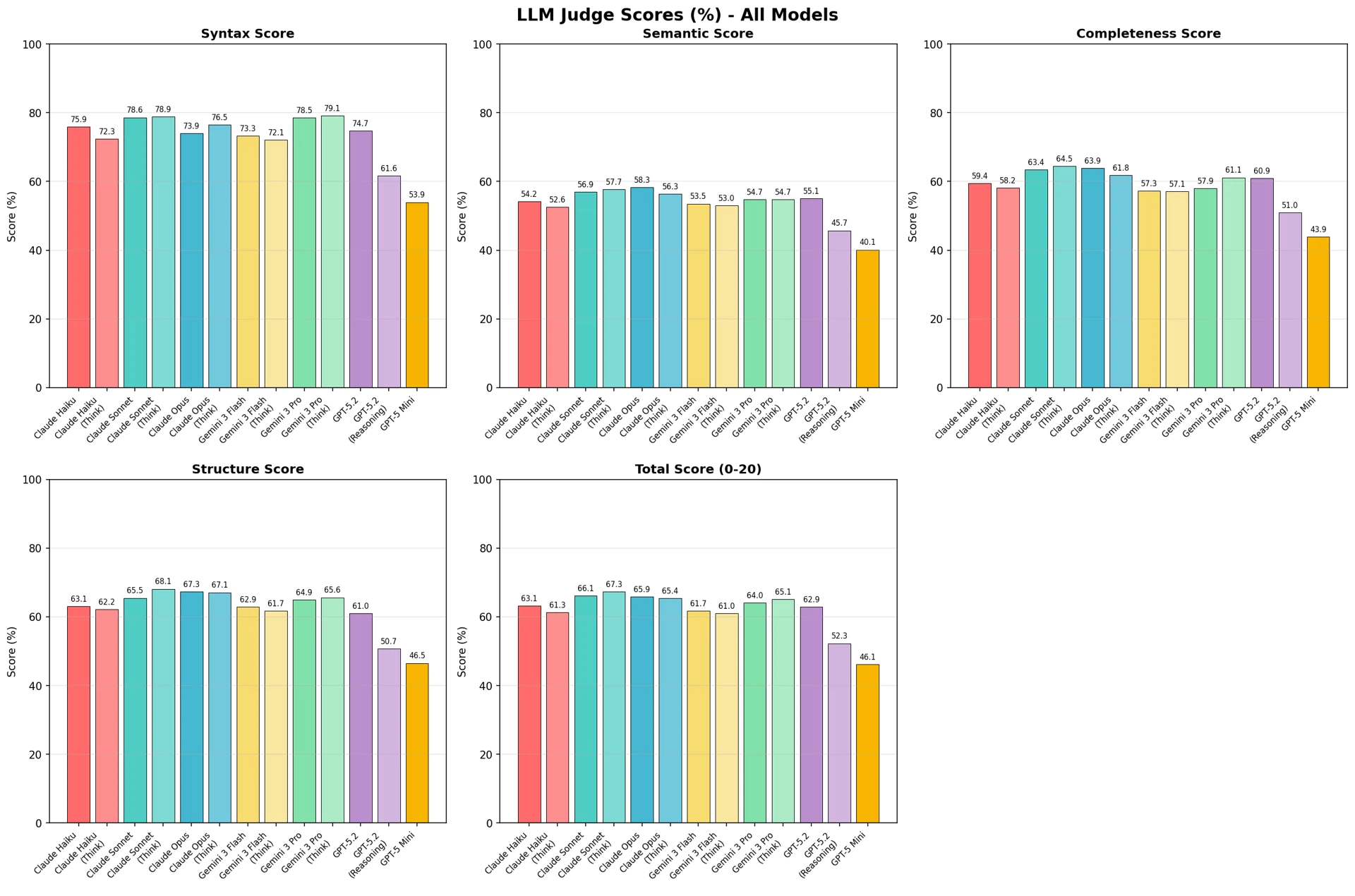
Figure 6: LLM-as-a-Judge scores (%) — comparison across all models
Think Mode Effect Analysis
Task-Specific Impact of Think Mode
Table 15 summarizes the performance changes associated with enabling Think mode for each model.
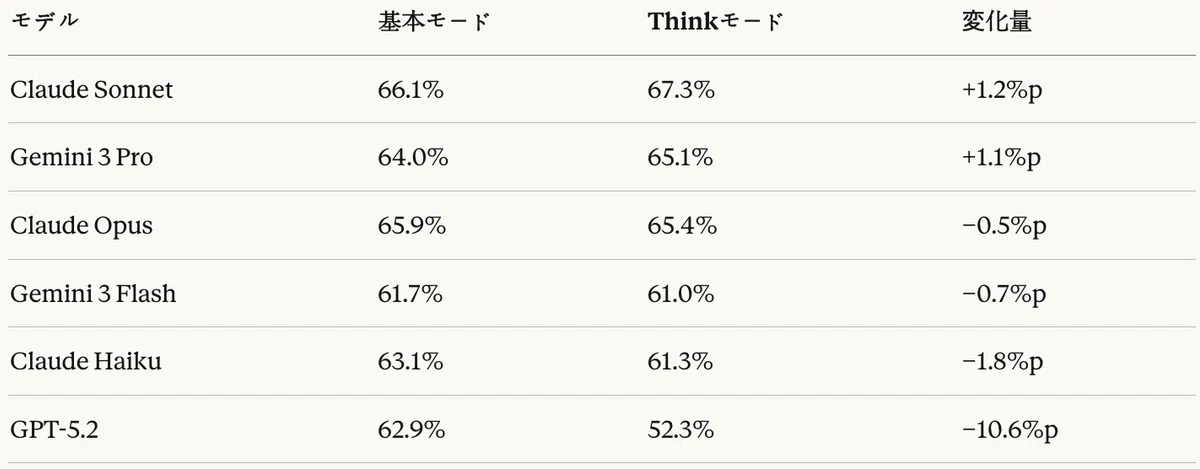
Table 15: Code generation task — effect of Think mode (based on total LLM-as-a-Judge score)
The effect of Think mode in the code generation task varied by model.
Positive effects
- Claude Sonnet improved by +1.2%p in Think mode, achieving the top overall score (67.3%)
- Gemini 3 Pro also improved by +1.1%p
Negative effects
- Claude Haiku declined by -1.8%p in Think mode
- GPT-5.2 experienced a severe performance drop of -10.6%p in Reasoning mode
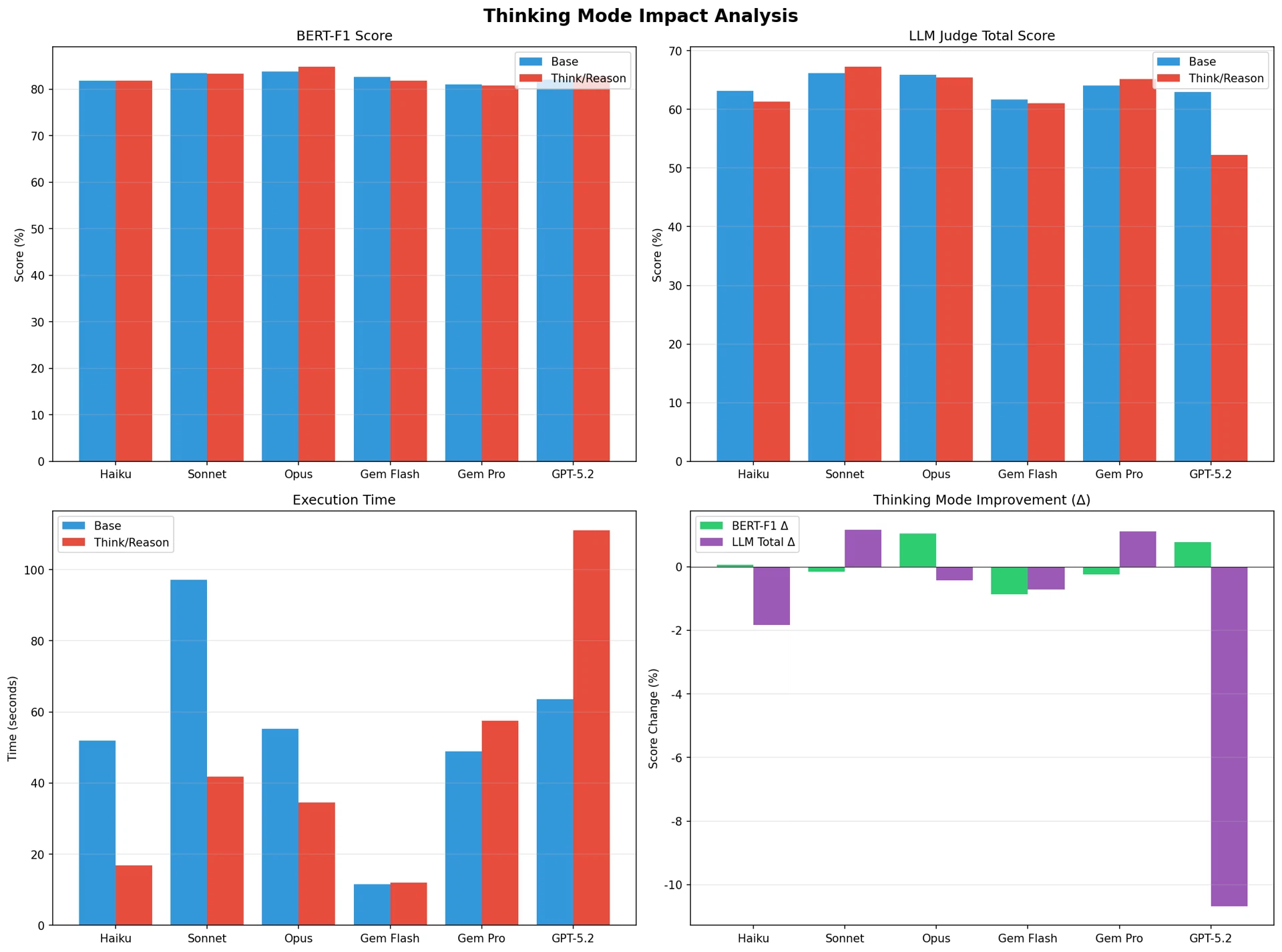
Figure 7: Thinking mode impact analysis
Interpreting the Effect of Think Mode
In the code generation task, Claude Sonnet's Extended Thinking produced a positive effect, while GPT's Reasoning mode led to a substantial performance decline. This can be interpreted as follows.
- Alignment with task characteristics: Code generation is a task where logical structuring and accurate syntax generation are critical, and Claude's Extended Thinking may be designed in a way that fits these requirements.
- Side effects of excessive reasoning: GPT's Reasoning mode is optimized for complex mathematical reasoning, so in standardized code generation tasks, excessive reasoning may actually become a hindrance.
- Stability issues: GPT-5.2 (Reasoning) showed a high empty-response rate, which led to a practical decline in performance.
Model Analysis
Empty Response Rate
In real operating environments, model stability is just as important as quality. Table 16 organizes the results of the stability analysis.
Specifically, the httpx client timeout was set to 300 seconds (5 minutes), and any case in which a response could not be completed within that time was counted as an "empty response."
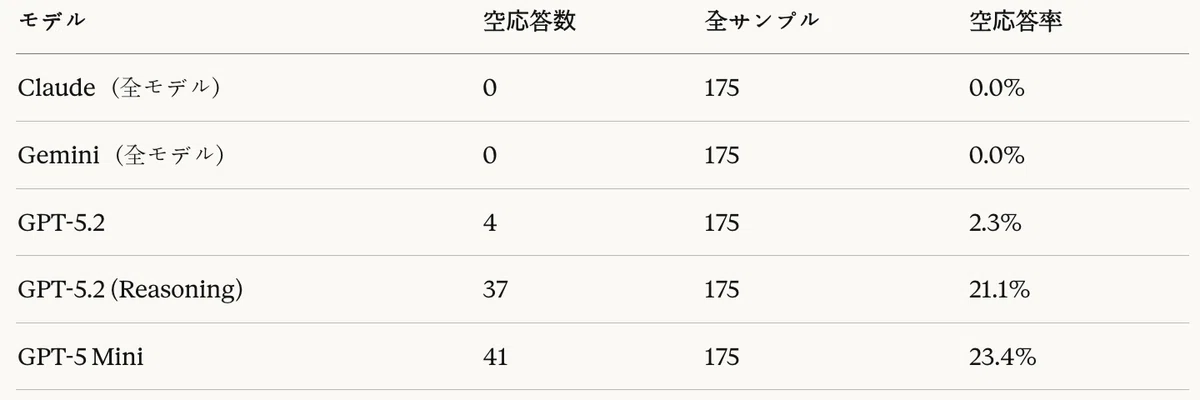
Table 16: Code generation task — empty response rate by model
According to the stability analysis, both Claude and Gemini models recorded a 0% empty-response rate, demonstrating complete stability. By contrast, GPT models exposed serious stability issues.
- GPT-5.2: 2.3% (4/175) empty responses, a level that warrants caution
- GPT-5.2 (Reasoning): 21.1% (37/175) empty responses, unsuitable for production use
- GPT-5 Mini: 23.4% (41/175) empty responses, unsuitable for production use
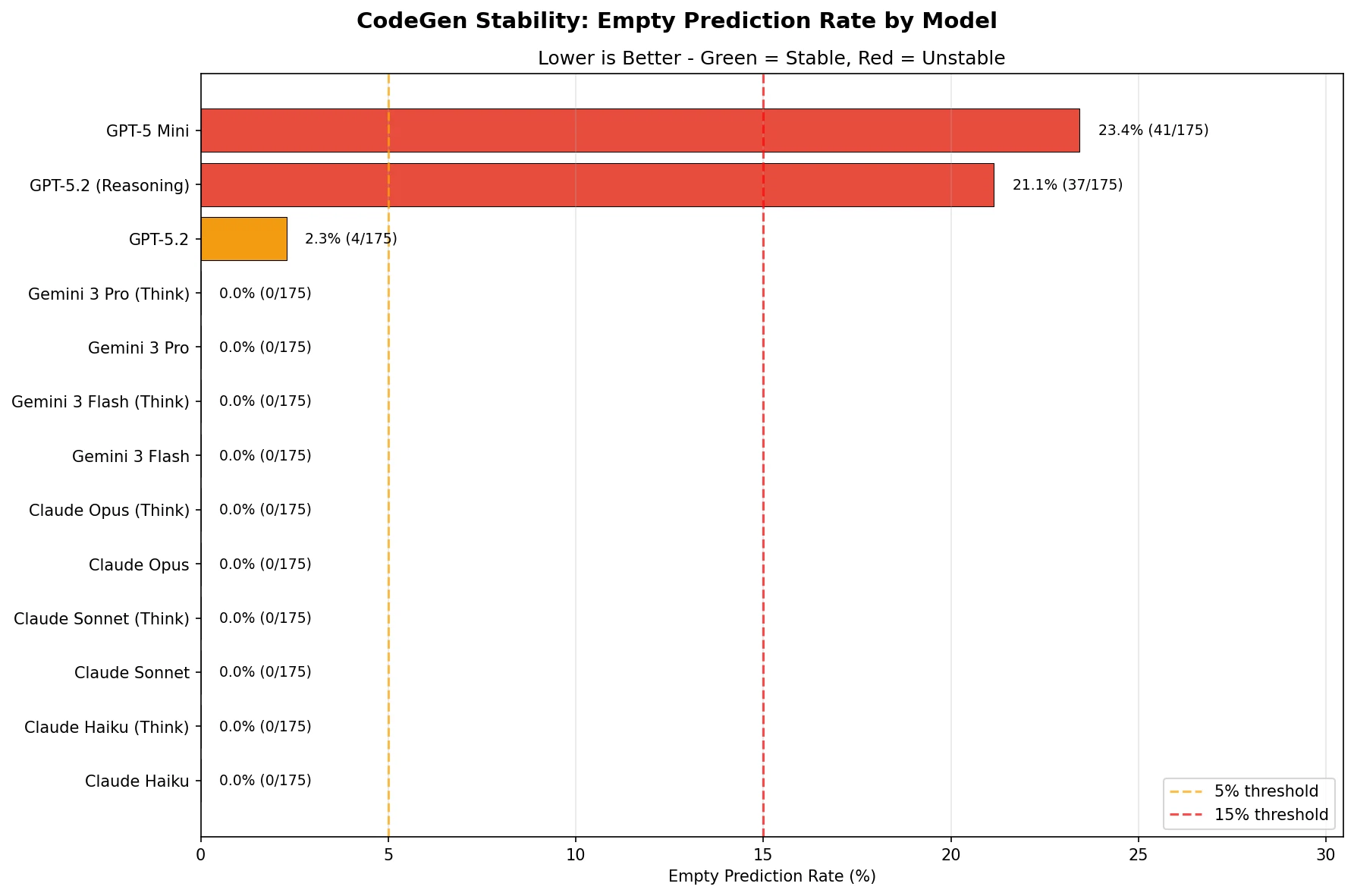
Figure 8: Code generation stability — empty response rate by model
Practical Impact of Stability
A high empty-response rate causes the following problems.
- Effective quality degradation: Because empty responses are scored as zero, the practical quality of GPT-5.2 (Reasoning) is even lower than its surface-level score suggests.
- Higher retry cost: When an empty response occurs, a retry is required, causing additional cost and delay.
- Lower system reliability: A failure rate above 20% is difficult to tolerate in a production environment.
Based on this analysis, we do not recommend GPT-5.2 (Reasoning) or GPT-5 Mini for use in a code-generation pipeline.
Cost-Quality Analysis
Cost and Cost Efficiency by Model
Table 17 organizes the cost and quality of each model per 1K requests.
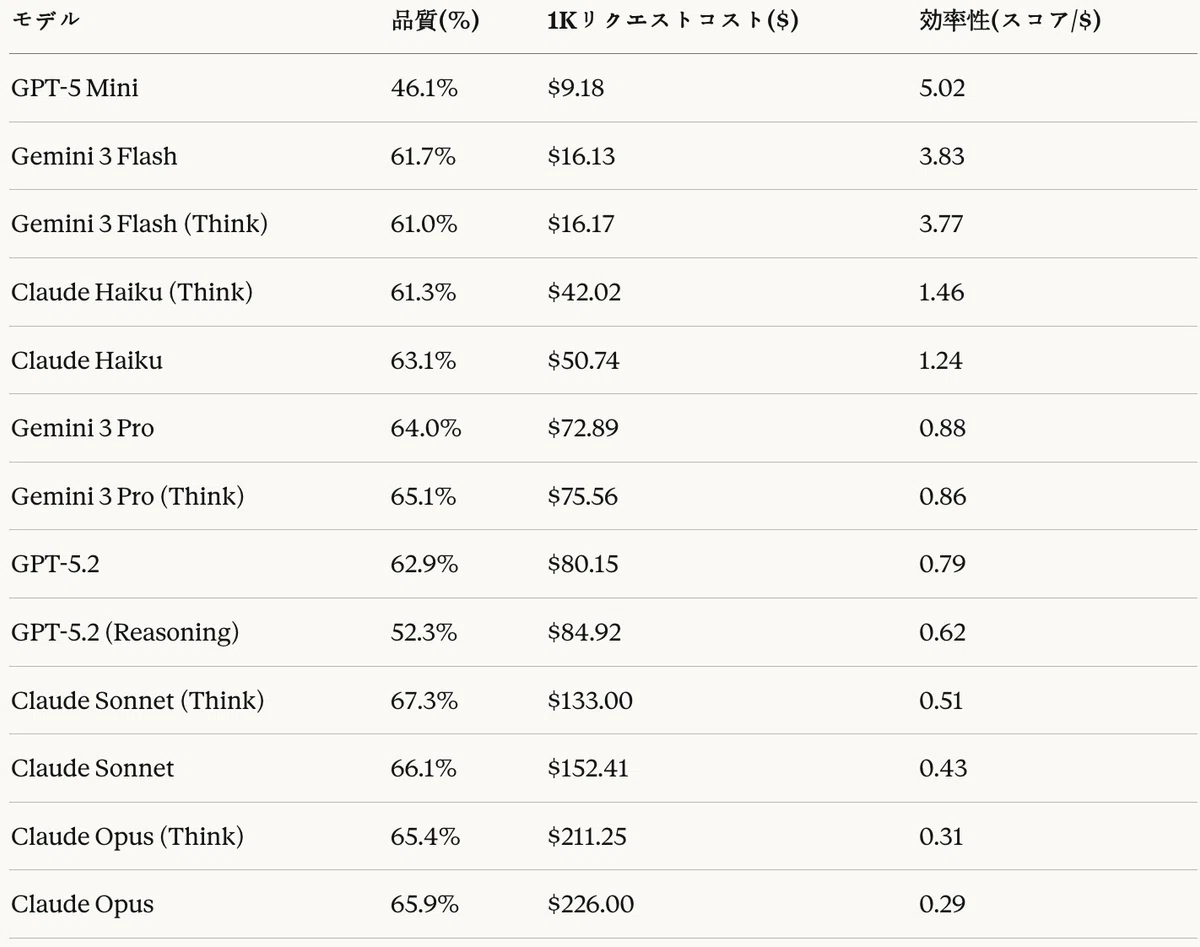
Table 17: Code generation task — cost analysis — efficiency = quality (%) / cost ($)
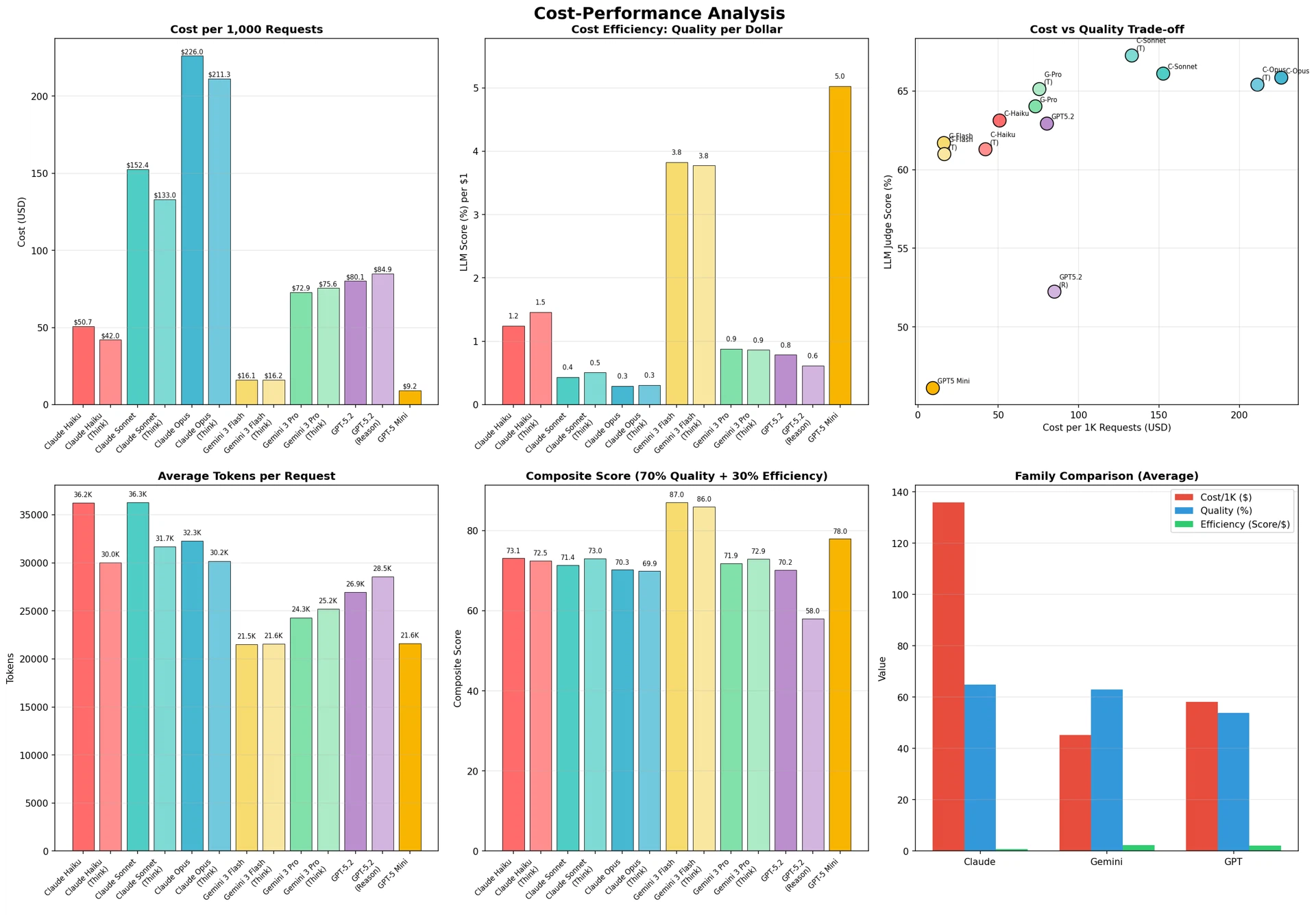
Figure 9: Cost-performance analysis
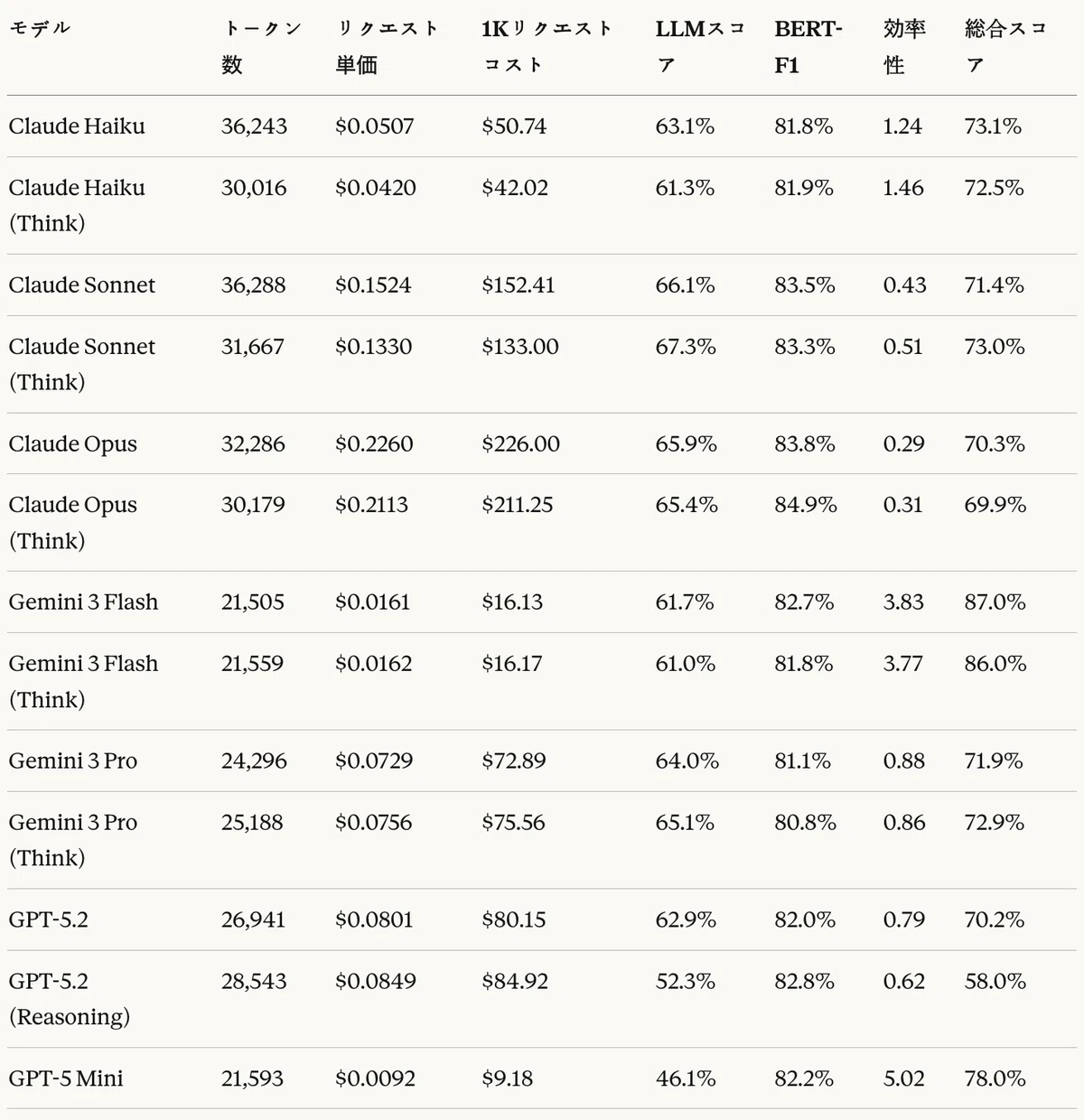
Cost-performance summary table
Cost-Quality Trade-off
From the cost-quality analysis, the following Pareto-optimal configurations were derived.
- Best low-cost option: Gemini 3 Flash ($16.13, 61.7%) — most efficient relative to cost (3.83 points/$)
- Best balanced option: Gemini 3 Pro (Think) ($75.56, 65.1%) — good quality at a reasonable cost
- Best top-quality option: Claude Sonnet (Think) ($133.00, 67.3%) — for cases where the highest quality is required
Summary
The evaluation results for the code generation task can be summarized as follows.
Quality ranking (based on LLM-as-a-Judge)
- Claude Sonnet (Think): 67.3%
- Claude Sonnet: 66.1%
- Claude Opus: 65.9%
- Claude Opus (Think): 65.4%
- Gemini 3 Pro (Think): 65.1%
Key findings
- Claude dominance: Claude models occupied the top ranks, with Claude Sonnet (Think) achieving the highest quality.
- Asymmetric effect of Think mode: Think mode showed positive effects for Claude Sonnet and Gemini 3 Pro (+1.1 to +1.2%p), but negative effects for Claude Haiku (-1.8%p) and strongly negative effects for GPT (-10.6%p).
- GPT stability issues: GPT-5.2 (Reasoning) and GPT-5 Mini recorded empty-response rates of 21.1% and 23.4%, respectively, making them unsuitable for use in a code-generation pipeline.
- Cost efficiency: Among stable models, Gemini 3 Flash provided 61.7% quality at the low cost of $16.13, making it the most cost-efficient option (3.83 points/$).

Table 18: Recommended models for the code generation task
In the next chapter, we analyze the evaluation results for the Agentic RAG task and compare how they differ from the code generation task.
Chapter 5. Experimental Results: Agentic RAG Task
This chapter presents the evaluation results for the Agentic RAG task of the MFID Mapping Agent. We analyze retrieval accuracy and efficiency, and examine the impact of Think mode as well as the differences from the code generation task.
Overall Quality Evaluation Results
Recall@K and MRR Results
Table 19 organizes the results of the main evaluation metrics.
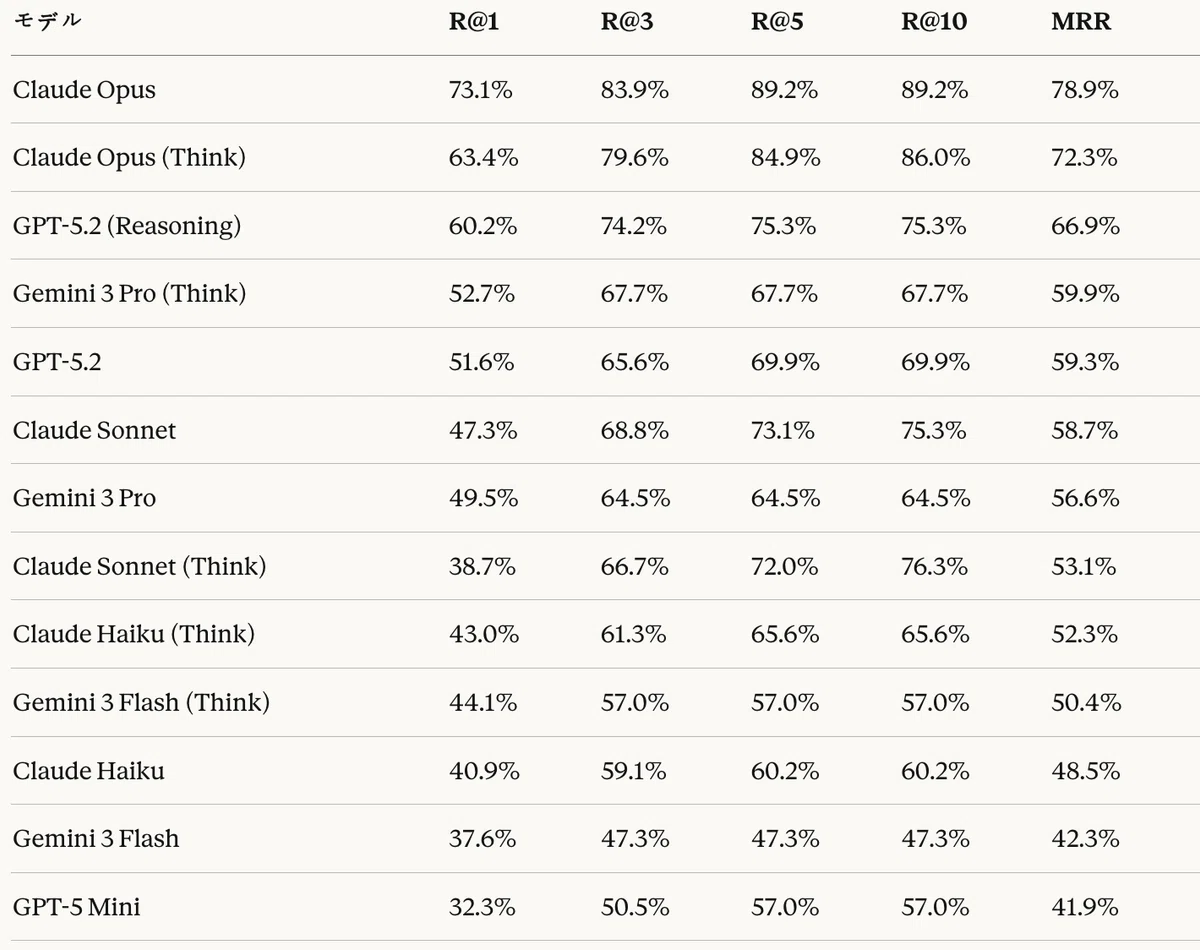
Table 19: Agentic RAG task — retrieval performance results
In the Agentic RAG task, Claude Opus ranked first with MRR 78.9%, R@1 73.1%, and R@10 89.2%. This was 6.6 percentage points higher than the second-place Claude Opus (Think) at 72.3%.
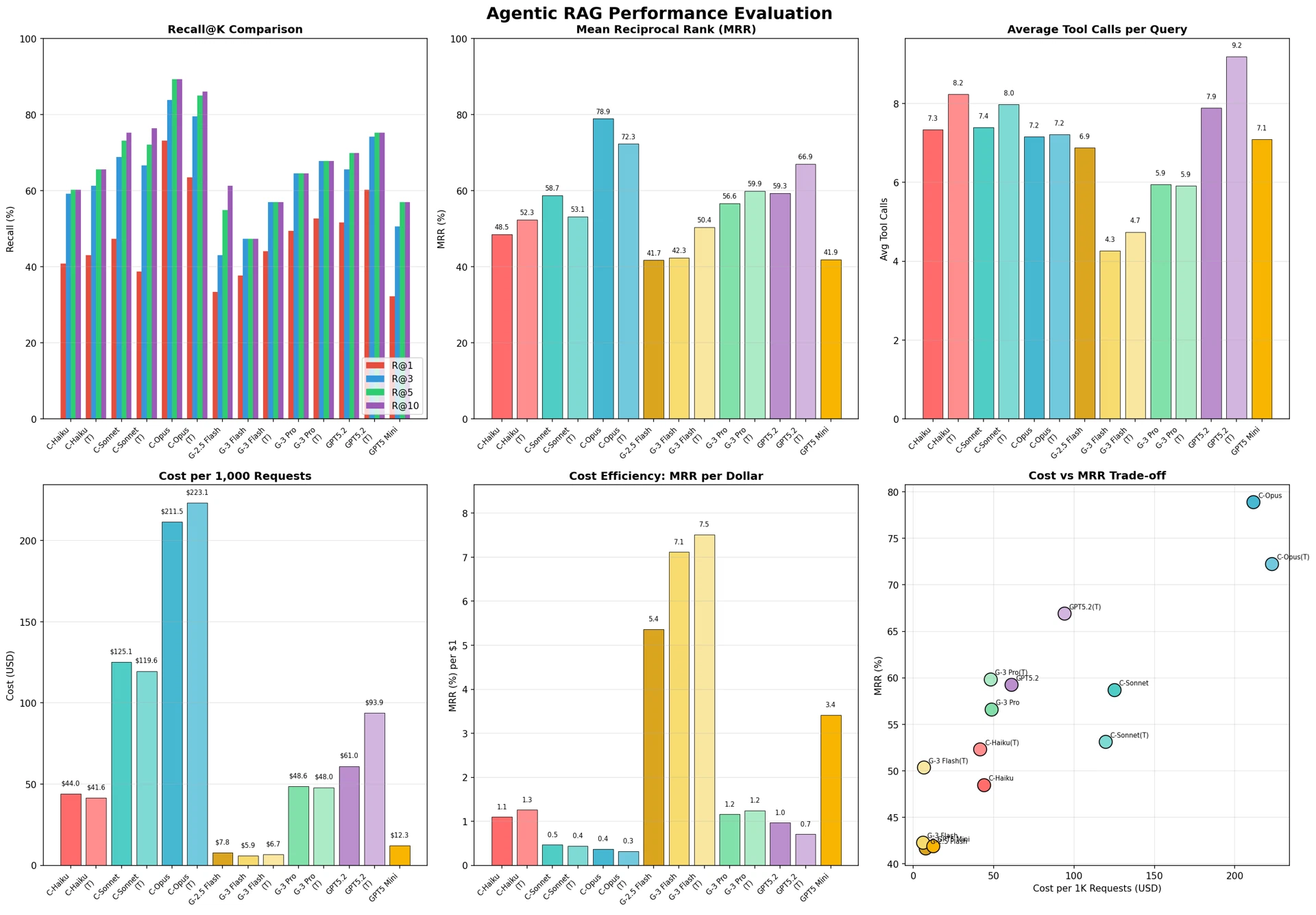
Figure 11: Agentic RAG performance evaluation
Unlike in the code generation task, it is noteworthy that GPT-5.2 (Reasoning) ranked third with 66.9%. This suggests that GPT's Reasoning mode is effective for complex retrieval and mapping reasoning.
Tool-Call Efficiency
Table 20 shows the average number of tool calls per query for each model.
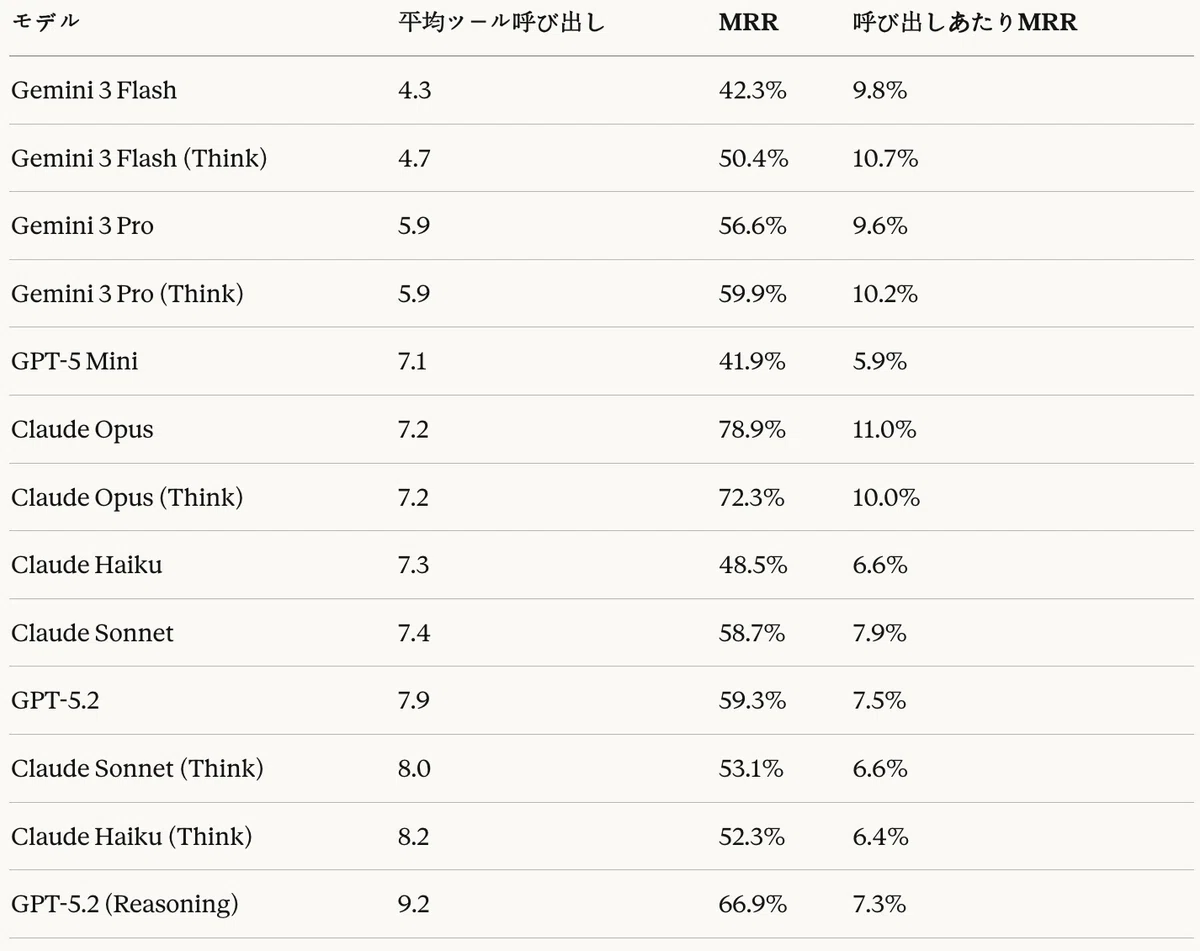
Table 20: Agentic RAG task — tool-call efficiency
Gemini models performed efficient retrieval with the fewest tool calls (4.3–5.9). By contrast, GPT-5.2 (Reasoning) made the most tool calls at 9.2, yet still achieved a high MRR of 66.9%.
In terms of MRR per call, Claude Opus (11.0%) was the most efficient, followed by Gemini 3 Flash (Think) at 10.7%. This means Claude Opus achieved the highest accuracy with an appropriate number of tool calls (7.2).
Agentic RAG Evaluation Summary
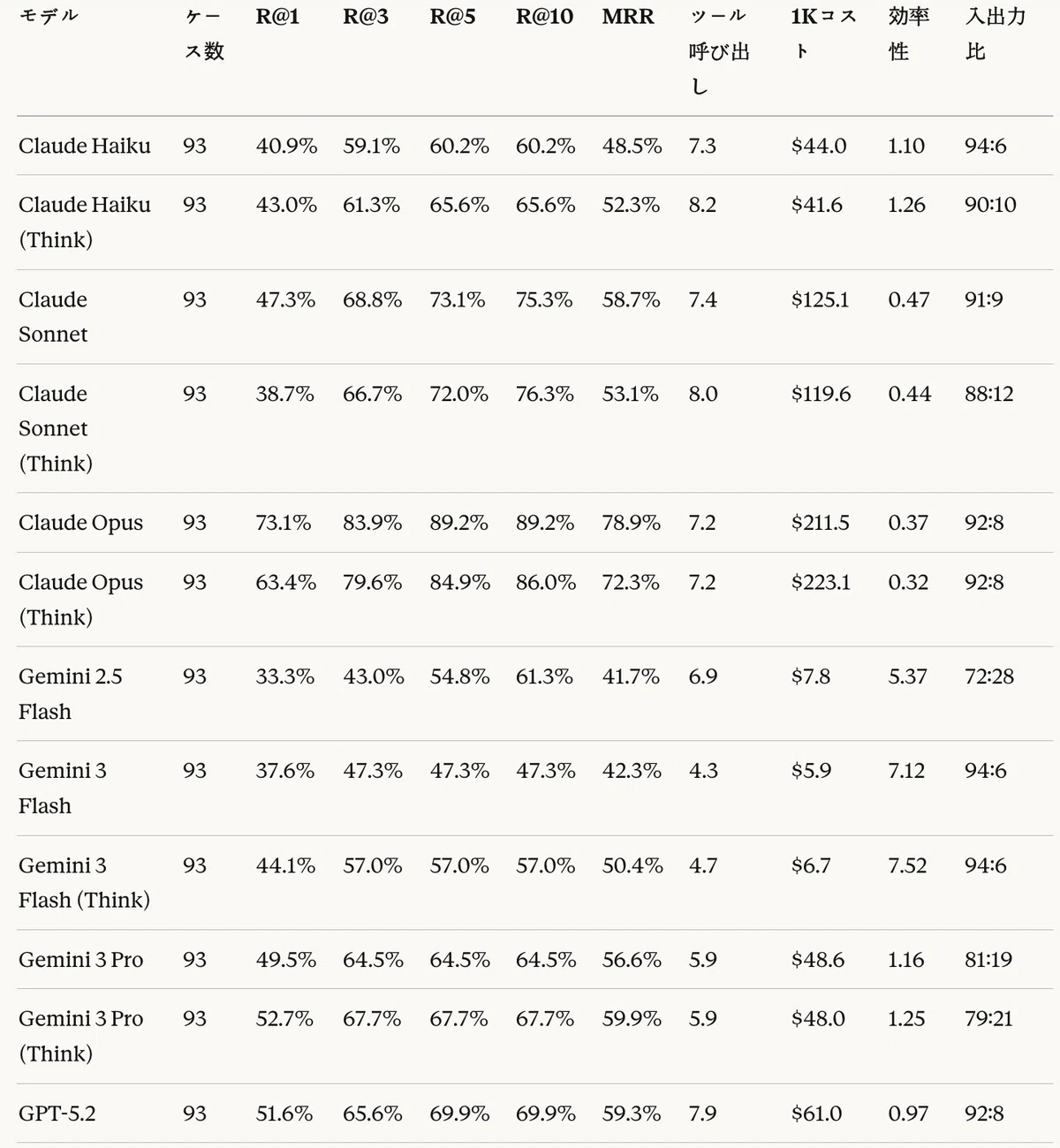
Agentic RAG evaluation summary

Agentic RAG evaluation summary (continued)
Think Mode Effect Analysis
Task-Specific Impact of Think Mode
Table 21 shows the change in MRR associated with enabling Think mode for each model.
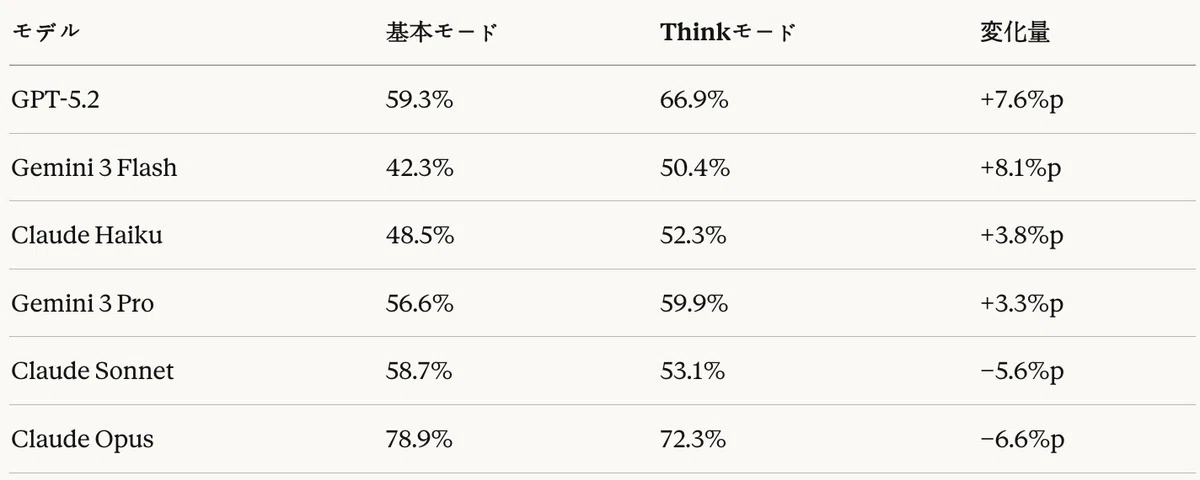
Table 21: Agentic RAG task — effect of Think mode (based on MRR)
The effect of Think mode in the Agentic RAG task showed the exact opposite pattern from the code generation task.
Positive effects
- Gemini 3 Flash: +8.1%p (largest improvement)
- GPT-5.2: +7.6%p (it was -10.6%p in code generation)
- Claude Haiku: +3.8%p
- Gemini 3 Pro: +3.3%p
Negative effects
- Claude Opus: -6.6%p (the base mode already had the best performance)
- Claude Sonnet: -5.6%p
Comparison of Think Mode Effects Across Tasks
Table 22 compares the effects of Think mode in the code generation and Agentic RAG tasks.
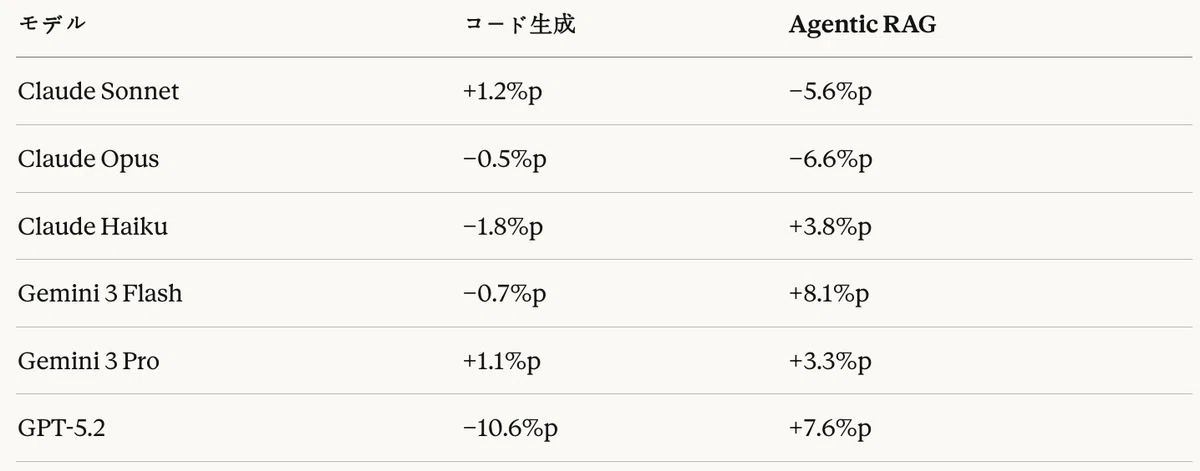
Table 22: Comparison of Think mode effects by task
The analysis highlights the completely opposite pattern of GPT-5.2.
- Code generation: -10.6%p (substantial decline)
- Agentic RAG: +7.6%p (meaningful improvement)
This result suggests that GPT's Reasoning mode is designed to better suit complex retrieval and reasoning tasks than standardized code generation.
Cost-Quality Analysis
Cost and Cost Efficiency by Model
Table 23 organizes the cost and cost efficiency of each model per 1K requests.
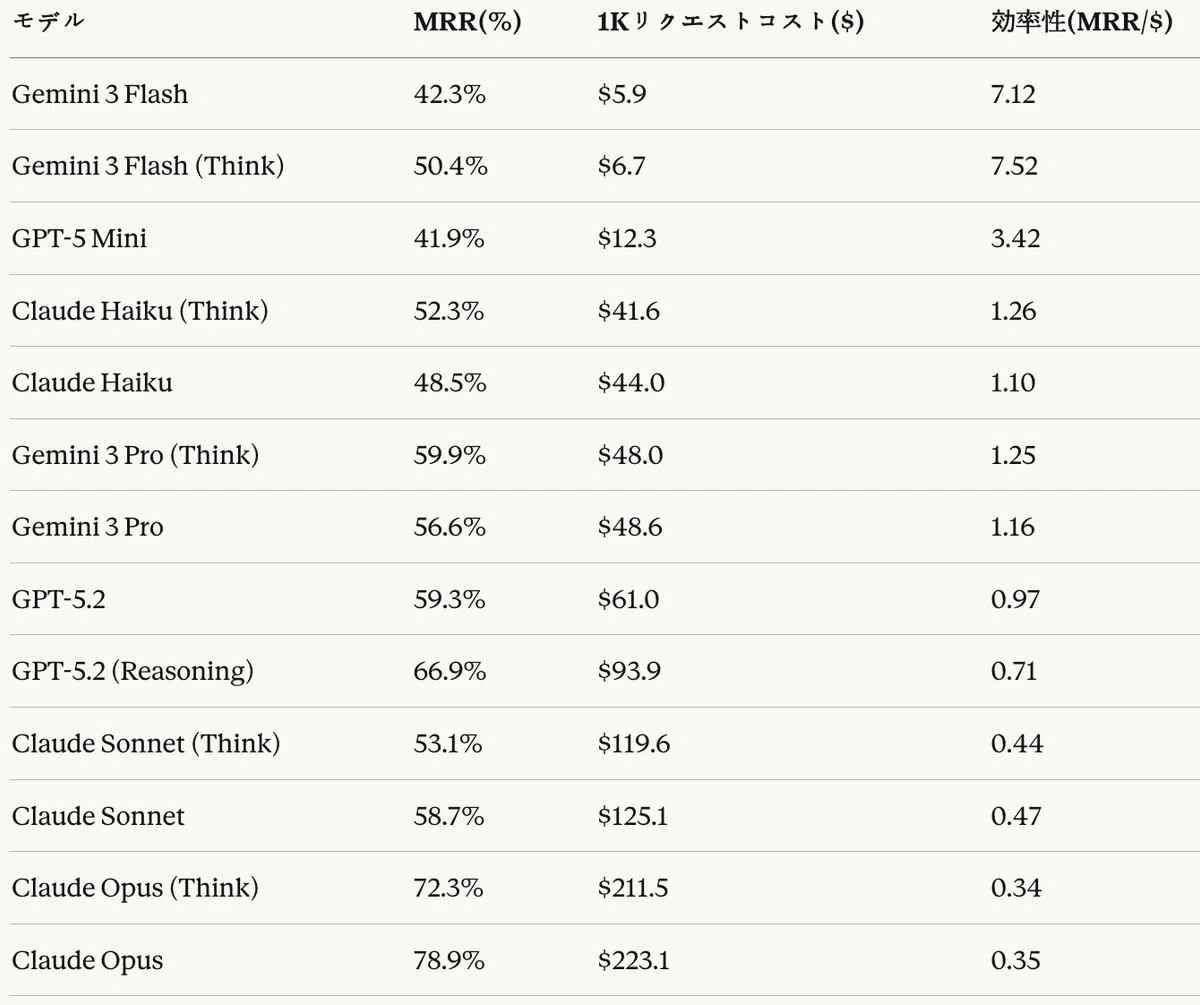
Table 23: Agentic RAG task — cost analysis — efficiency = MRR (%) / cost ($)
Cost-Quality Trade-off
From the cost-quality analysis, the following Pareto-optimal configurations were derived.
- Best low-cost option: Gemini 3 Flash (Think) ($6.7, 50.4%) — the highest cost efficiency (7.52 MRR/$)
- Best balanced option: Gemini 3 Pro (Think) ($48.0, 59.9%) — good quality at a reasonable cost
- Best top-quality option: Claude Opus ($223.1, 78.9%) — for cases where the highest MRR is required
Compared with the code generation task, Agentic RAG differs in that Gemini 3 Flash (Think) is more efficient than its base mode, and Claude Opus base mode outperforms its Think mode.
Code Generation vs. Agentic RAG Comparison
Changes in Model Ranking
Table 24 compares model rankings across the two tasks.
Table 24: Comparison of model rankings by task (top 5)
Main changes:
- Claude Opus: 3rd in code generation → 1st in Agentic RAG
- GPT-5.2 (Reasoning): 12th in code generation → 3rd in Agentic RAG (up 9 positions)
- Claude Sonnet (Think): 1st in code generation → 8th in Agentic RAG
Model Suitability by Task Characteristics
When the results of the two tasks are considered together, the following patterns emerge.
Models strong in code generation
- Claude Sonnet (Think): strong at producing structured outputs
- Claude Sonnet: stable code quality
Models strong in Agentic RAG
- Claude Opus: strong in complex domain reasoning
- GPT-5.2 (Reasoning): effective for multi-step retrieval reasoning
Models balanced across both tasks
- Gemini 3 Pro (Think): within the upper ranks in both tasks
- GPT-5.2: in the upper-middle ranks in both tasks
Summary
The evaluation results for the Agentic RAG task can be summarized as follows.
Quality ranking (based on MRR)
- Claude Opus: 78.9%
- Claude Opus (Think): 72.3%
- GPT-5.2 (Reasoning): 66.9%
- Gemini 3 Pro (Think): 59.9%
- GPT-5.2: 59.3%
Key findings
- Claude Opus dominance: Claude Opus ranked first with an MRR of 78.9%, which was 6.6%p higher than second place.
- GPT Reasoning reversal: GPT-5.2 (Reasoning), which had ranked near the bottom in code generation, placed third in Agentic RAG, showing task-specific differences in suitability.
- Opposite effect of Think mode: Unlike in code generation, the Think modes of GPT and Gemini showed positive effects in Agentic RAG, while Claude's higher-end models (Opus and Sonnet) instead showed negative effects.
- Cost efficiency: Gemini 3 Flash (Think) provided an MRR of 50.4% at the low cost of $6.7, making it the most cost-efficient option (7.52 MRR/$).

Table 25: Recommended models for the Agentic RAG task
In the next chapter, we synthesize the results of the two tasks and present pipeline optimization strategies and final recommendations.
Chapter 6. Integrated Analysis and Recommendations
This chapter synthesizes the results of the two tasks—code generation and Agentic RAG—and presents a pipeline optimization strategy. It summarizes the characteristics of each model and derives final recommendations that take the cost-quality trade-off into account.
Overall Pipeline Analysis
Stage-by-Stage Performance Comparison
Table 26 organizes the performance of each model across the two tasks and their overall quality.
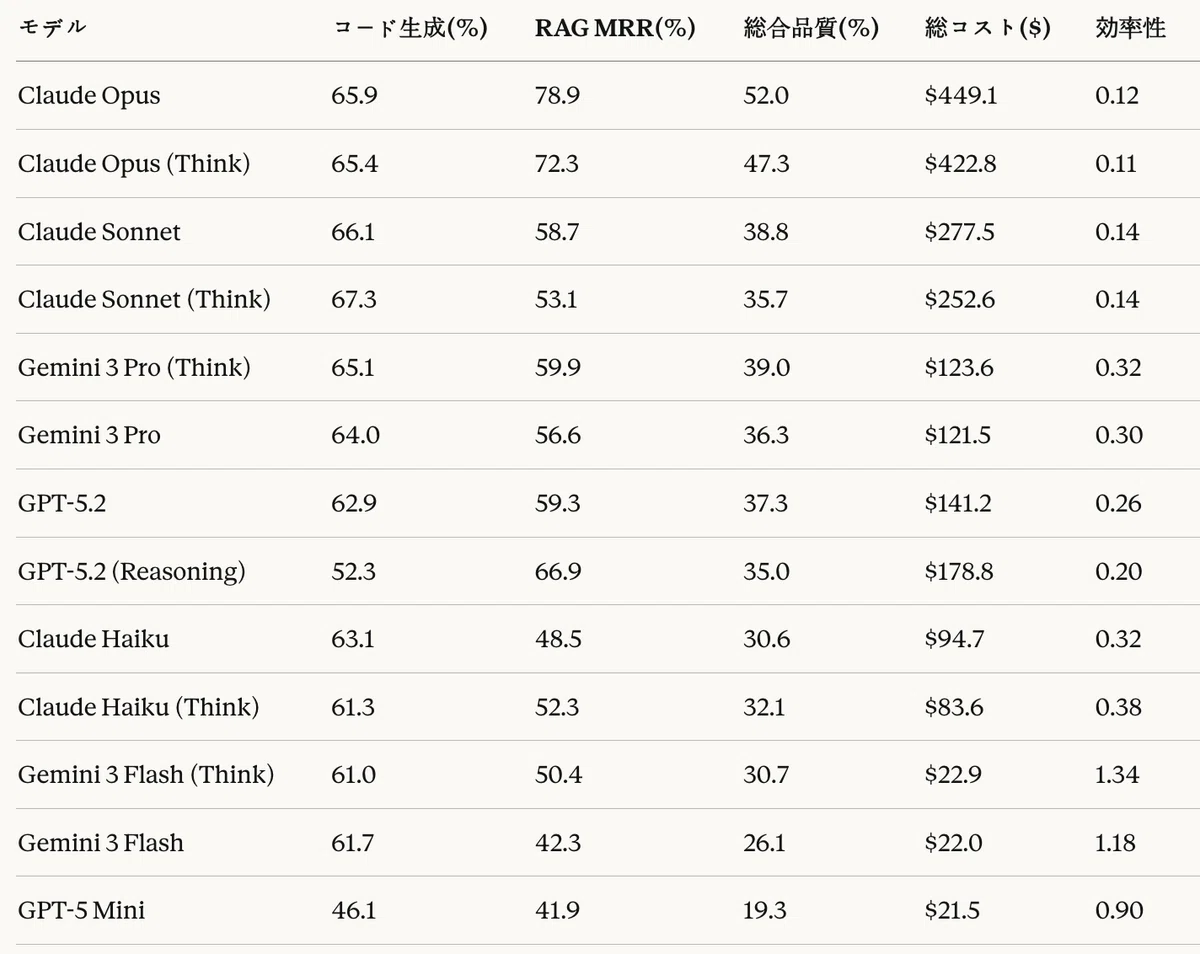
Table 26: Overall pipeline performance analysis
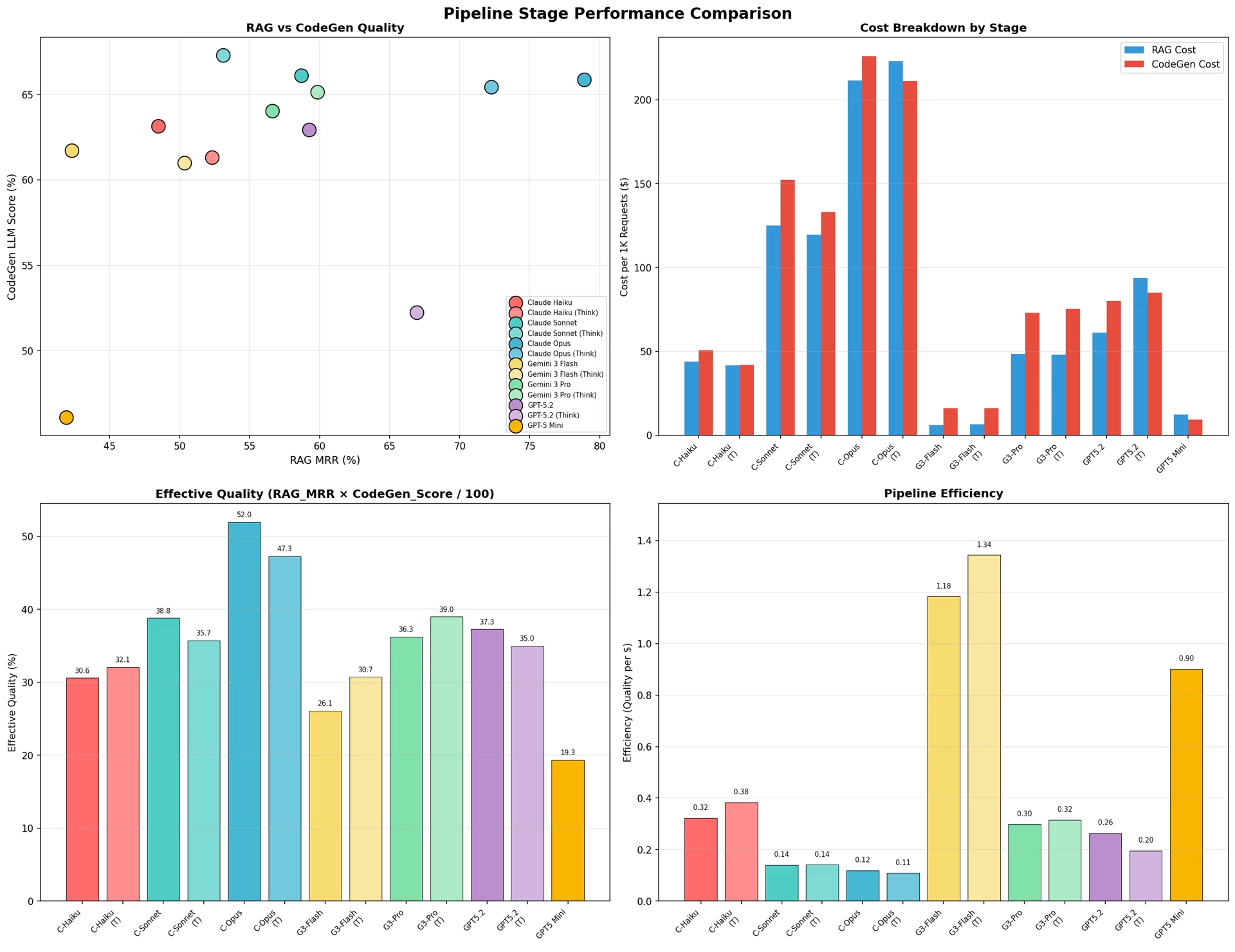
Figure 13: Performance comparison by pipeline stage
Effective Quality Analysis
In terms of overall quality, Claude Opus ranked highest at 52.0%, because it showed strong performance in both code generation (65.9%) and RAG (78.9%). However, because it also had the highest total cost ($449.1), its efficiency (0.12) was low.
In terms of cost efficiency, Gemini 3 Flash (Think) was the best at 1.34. This is because it achieved a good overall quality score (30.7%) at a low cost ($22.9).
Summary of Model Characteristics
Individual Model Characteristics
Claude Opus
- Code generation: 3rd (65.9%)
- Agentic RAG: 1st (78.9%)
- Characteristics: top-tier in both tasks, strong in complex domain reasoning
- Recommended for: cases where the highest quality is required
Claude Sonnet (Think)
- Code generation: 1st (67.3%)
- Agentic RAG: 8th (53.1%)
- Characteristics: specialized for code generation, with Think mode proving effective
- Recommended for: cases where code-generation quality is important
Gemini 3 Flash (Think)
- Code generation: 11th (61.0%)
- Agentic RAG: 10th (50.4%)
- Characteristics: lowest cost, highest efficiency
- Recommended for: cases with tight budget constraints
GPT-5.2 (Reasoning)
- Code generation: 12th (52.3%)
- Agentic RAG: 3rd (66.9%)
- Characteristics: extreme differences in performance by task, unstable in code generation
- Recommended for: standalone use in RAG tasks only
Overall Effect of Think Mode
Task-Specific Impact of Think Mode
Table 27 summarizes the task-specific effects of Think mode.
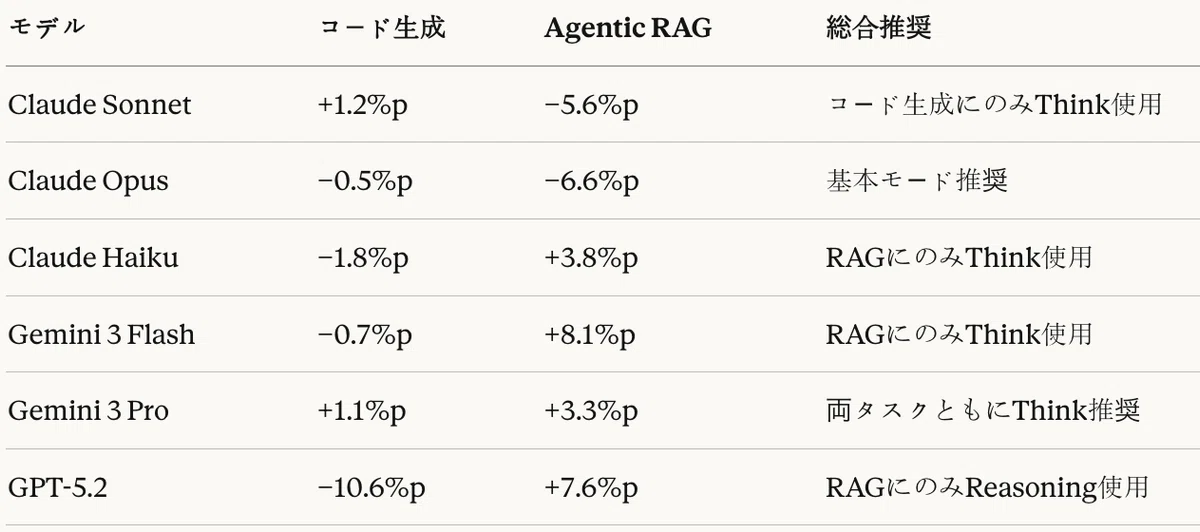
Table 27: Overall summary of Think mode effects
Think mode strategy
Because the effect of Think mode differs by task, a heterogeneous pipeline strategy is effective.
- Code generation stage: Claude Sonnet (Think) or Gemini 3 Pro (Think)
- Agentic RAG stage: Claude Opus (base) or Gemini 3 Flash (Think)
This strategy makes it possible to achieve optimal performance at each stage.
Pipeline Optimization Strategy
Pipeline Combination Analysis
Because the AI Check system executes code generation and Agentic RAG sequentially, different models can be applied to each stage. From among 13 models × 13 models = 169 combinations, Pareto-optimal combinations were derived.
Recommended Pipeline Configurations
Table 28 shows the recommended pipeline configurations by scenario.

Table 28: Recommended pipeline configurations by scenario — current configuration (Claude Sonnet + Claude Sonnet): quality approx. 62%, cost approx. $277
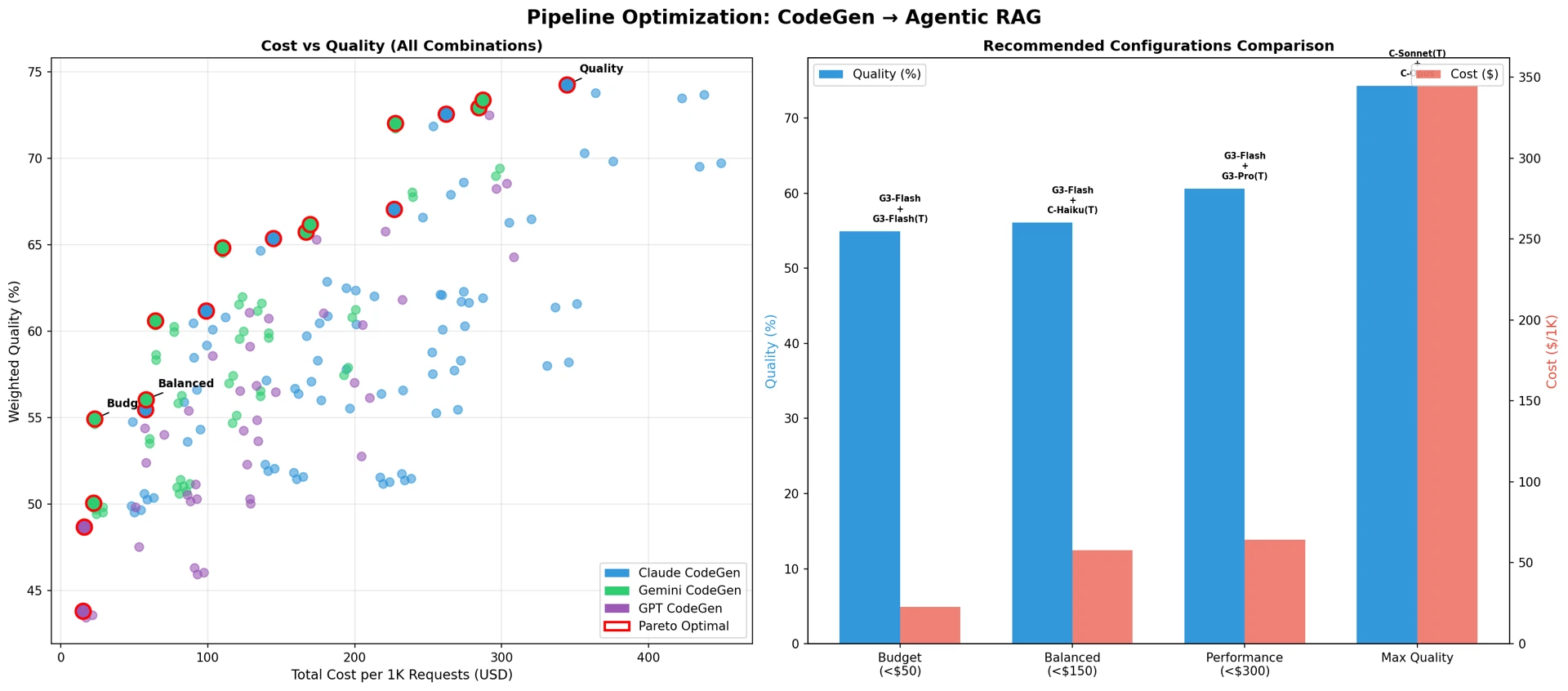
Figure 14: Pipeline optimization: CodeGen → Agentic RAG
Optimization Effects
Improvements of the recommended configurations over the current single-model Claude Sonnet setup:
Budget configuration (Gemini 3 Flash + Gemini 3 Flash (Think))
- Cost: $277 → $23 (92% reduction)
- Quality: 62% → 54% (8%p decrease)
- Cost efficiency: 10× improvement
Balanced configuration (Gemini 3 Flash + Claude Haiku (Think))
- Cost: $277 → $58 (79% reduction)
- Quality: 62% → 65% (3%p improvement)
- Cost efficiency: 5× improvement
Highest-quality configuration (Claude Sonnet (Think) + Claude Opus)
- Cost: $277 → $356 (29% increase)
- Quality: 62% → 74% (12%p improvement)
- Cost per unit of quality: improved
Final Recommendations
Answers to the Research Questions
RQ1: How large are the performance differences among LLM models in domain-specific tasks?
The performance differences among models are significant, and the best model differs depending on the task type.
- Code generation: Claude Sonnet (Think) > Claude Sonnet > Claude Opus
- Agentic RAG: Claude Opus > Claude Opus (Think) > GPT-5.2 (Reasoning)
RQ2: How do Think/Reasoning modes affect each task?
The effect of Think mode differs by task, and in some models it shows completely opposite patterns.
- GPT-5.2: code generation -10.6%p, Agentic RAG +7.6%p
- Claude Opus: base mode performs better in both tasks
RQ3: What is the optimal configuration in the cost-quality trade-off?
A heterogeneous model pipeline is more efficient than a homogeneous model pipeline.
- Balanced configuration: Gemini 3 Flash (code generation) + Claude Haiku (Think) (RAG)
- Achieved both 79% cost reduction and a 3%p quality improvement at the same time
RQ4: What factors should be considered in production environments?
Stability is an important factor, and the high empty-response rates of GPT models (21–23%) make them unsuitable for production use. Claude and Gemini models were stable, with 0% empty-response rates.
Practical Application Guidelines
When using a single model

Guidelines for using a single model
When using a heterogeneous model pipeline
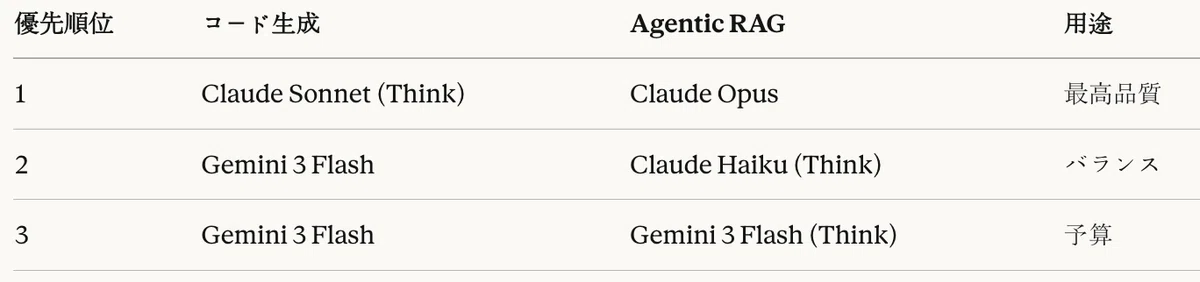
Guidelines for using a heterogeneous model pipeline
Summary
In this chapter, we integrated the results of the two tasks—code generation and Agentic RAG—and derived the following conclusions.
- Effectiveness of heterogeneous model pipelines: It was confirmed that combining models optimized for each task can simultaneously achieve lower cost and higher quality.
- Selective application of Think mode: Think mode does not guarantee universal benefits, so selective application that considers task and model characteristics is required.
- Importance of stability: In addition to quality, stability metrics such as empty-response rate also serve as core considerations in production model selection.
- Cost efficiency: Gemini models showed an advantage in cost efficiency, making them effective options in budget-constrained environments.
Conclusion
Summary of the Study
This study conducted a comparative evaluation of 13 model configurations from the three major LLM providers—Anthropic, Google, and OpenAI—using AI Check, a Japanese payroll system. It analyzed quality, cost, and stability for two tasks: natural language-to-CTE pseudocode conversion (code generation, 175 samples) and domain term-to-MFID mapping (Agentic RAG, 93 samples).
In the code generation task, Claude Sonnet (Think) achieved the highest performance at 67.3%, while in the Agentic RAG task, Claude Opus ranked first with an MRR of 78.9%. The effects of Think/Reasoning mode differed depending on task type, and GPT-5.2 showed conflicting patterns: -10.6%p in code generation and +7.6%p in Agentic RAG.
The cost-quality analysis confirmed that a heterogeneous pipeline is more efficient than a homogeneous one. The balanced configuration combining Gemini 3 Flash (code generation) and Claude Haiku (Think) (Agentic RAG) achieved a 79% cost reduction and a 3%p quality improvement compared with the single-model Claude Sonnet setup.
Main Contributions
The contributions of this study can be organized as follows.
First, it conducted a comparative LLM evaluation grounded in a real enterprise environment. Unlike previous studies that rely on general benchmarks, this study evaluated 13 LLM configurations on an active Japanese payroll-system pipeline and empirically compared model performance on domain-specific tasks.
Second, it clarified model characteristics across two different task types: code generation and Agentic RAG. It demonstrated that even the same model can shift significantly in ranking depending on task type, and confirmed that the effects of Think/Reasoning mode can appear in completely opposite directions depending on the task.
Third, it proposed a multidimensional evaluation framework. By combining traditional text metrics (BLEU, ROUGE-L, BERT-F1) with a four-dimensional LLM-as-a-Judge evaluation (syntactic correctness, semantic equivalence, condition completeness, and structural similarity), the study measured code generation quality from multiple angles. For Agentic RAG, it evaluated Recall@K, MRR, and tool-call efficiency.
Fourth, it presented a pipeline optimization strategy based on the cost-quality trade-off. By analyzing 169 pipeline combinations, it derived optimal configurations by scenario and demonstrated the effectiveness of heterogeneous model pipelines.
Practical Implications
The results of this study provide the following implications for practitioners developing LLM-based enterprise systems.
Task dependence of model selection: The assumption that a single model is optimal for all tasks has little support. Because the optimal model can vary by task, separate model evaluations are required for each stage of the pipeline.
Selective application of Think mode: It cannot be assumed that Think/Reasoning mode universally improves performance. Because performance degradation can be observed in some model-task combinations, prior validation is essential.
Importance of stability evaluation: Model selection based only on quality metrics can cause problems in production environments. The high empty-response rates of GPT models (21–23%) act as a limiting factor for production use regardless of their quality scores.
Consideration of cost efficiency: The highest-quality model is not always the best choice. Lower-cost models such as Gemini 3 Flash can provide sufficient quality while achieving more than 10× greater cost efficiency.
Limitations of the Study
This study has the following limitations.
First, it is a single-domain evaluation. The evaluation is limited to the specific domain of a Japanese payroll system, and additional validation is required before generalizing to other domains or languages.
Second, it uses a static evaluation dataset. The 175 code-generation samples and 93 RAG samples may not cover all real system scenarios. Building expanded datasets that include varying complexity and edge cases is necessary.
Third, it is a single-point-in-time evaluation. Given that LLMs are continuously updated, the results of this study are limited to the model versions available at the time of evaluation. A continuous evaluation framework is needed to track performance changes as model versions change.
Fourth, it is a single-turn evaluation. This study evaluates only single-turn responses for each sample, excluding multi-turn interaction and error-recovery capability from the scope of evaluation.
Future Research Directions
Building on this study, the following follow-up research directions are possible.
Multi-domain expansion: In addition to payroll systems, the evaluation should be extended to enterprise domains such as accounting, HR, and logistics in order to verify the generalizability of model characteristics.
Dynamic model selection: Developing routing mechanisms that select the optimal model in real time according to input complexity and type could enable dynamic optimization of cost and quality.
Multi-turn agent evaluation: Rather than evaluating only single-turn responses, future work should assess agent performance in multi-turn interactions and develop agent evaluation frameworks that include error recovery, clarification questions, and iterative improvement capability.
Continuous evaluation pipeline: Building a CI/CD-based evaluation pipeline that automatically tracks performance changes caused by model version updates would make rapid reevaluation and decision-making possible whenever models are updated.
Cost prediction models: Developing models that predict the cost and quality of each model based on input characteristics (length, complexity, domain) could make request-level optimal model selection feasible.
Closing Remarks
This study highlights the importance of systematic model evaluation and selection in LLM-based enterprise system development. Neither a single benchmark nor official provider performance indicators alone are sufficient to predict performance on real domain tasks, and customized evaluation that considers differences by task and mode is essential.
In systems with multi-stage pipelines, combining heterogeneous models can improve both cost efficiency and quality at the same time. We hope that the evaluation framework and optimization strategy proposed in this study will serve as a useful reference for the development of LLM-based enterprise systems.
📖 For the research background, system architecture, and experimental design discussed in this article, please refer to Part 1.
🚀 Try QueryPie AI now